Introducing Sig by Syndica, an RPS-focused Solana validator client written in Zig

What is Sig?
Sig is an intelligently optimized Solana validator implementation written in Zig, a cutting-edge low-level programming language.
Sig is a step function improvement in RPS
For every ‘write’ sendTransaction RPC call triggered on a node, 25 'read' calls are triggered. According to data covering a 2+ year period across a large variety of DApps that use Syndica, 96.1% of all calls made to a node are reads. Nevertheless, when discussing throughput, most attention is paid to the transactions-per-second (TPS) metric. Sig is built with a different paradigm in mind: optimizing reads-per-second (RPS).
A validator client built with the end-user in mind must prioritize a smooth user experience not only when they click the ‘Submit Transaction’ button, but also from the moment they load the page, to when they make their decision to submit their transaction, through when they review the updated wallet balances following the transaction. Blockchain user experience must be robust and ‘snappy’ end-to-end.
The importance of fast, reliable reads will only increase - as blockchains scale and more and more of the digital world is stored on-chain, reads will place disproportionately larger demands on L1s. How does Solana perform on this dimension today? Unfortunately, not as well as the leading alternative chain - Ethereum.
Solana nodes fall behind frequently compared to Ethereum nodes. Below is a study comparing slot lag across both public and private RPC providers over the last 90 days, in each of the Solana and Ethereum ecosystems.
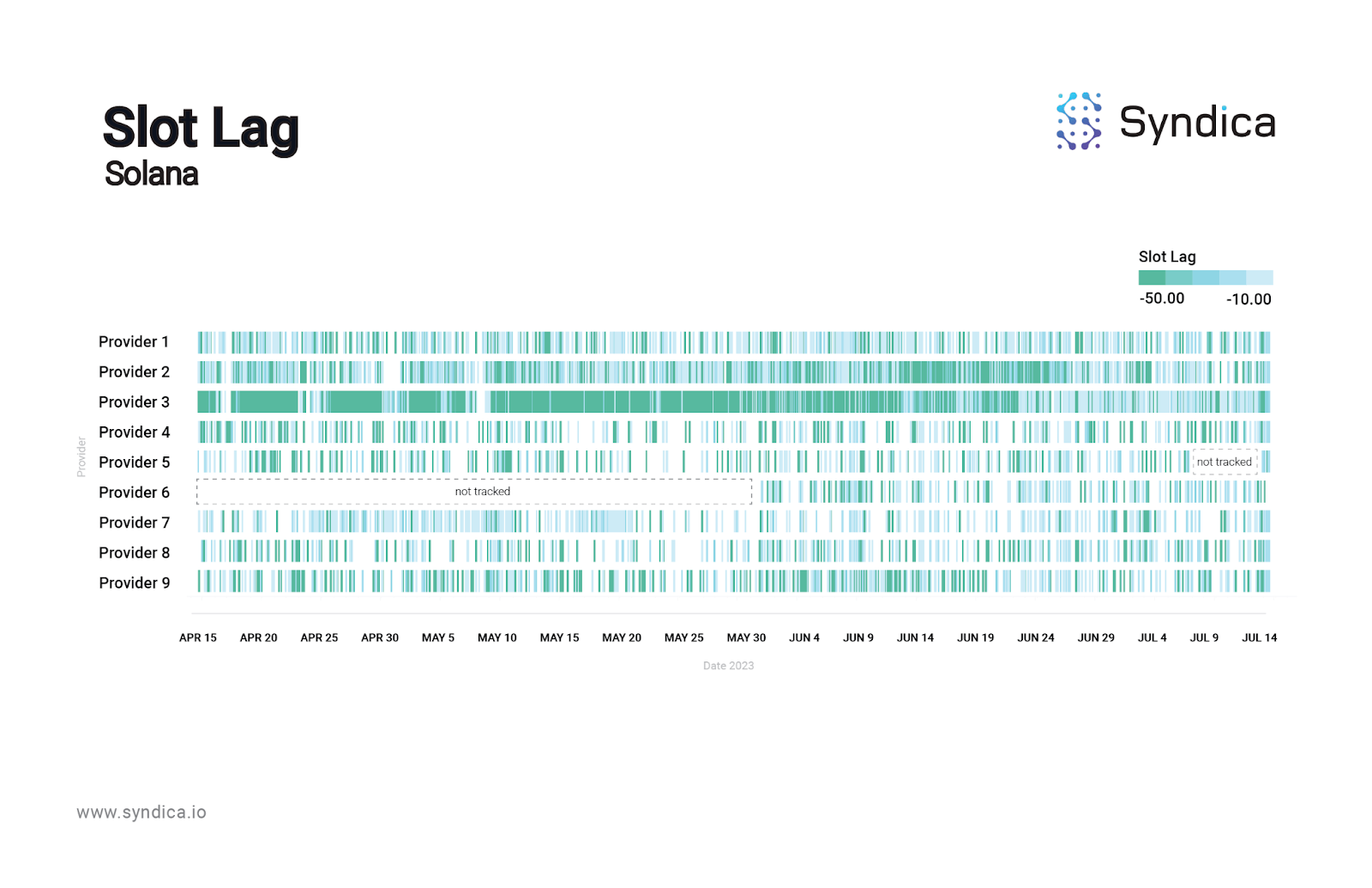
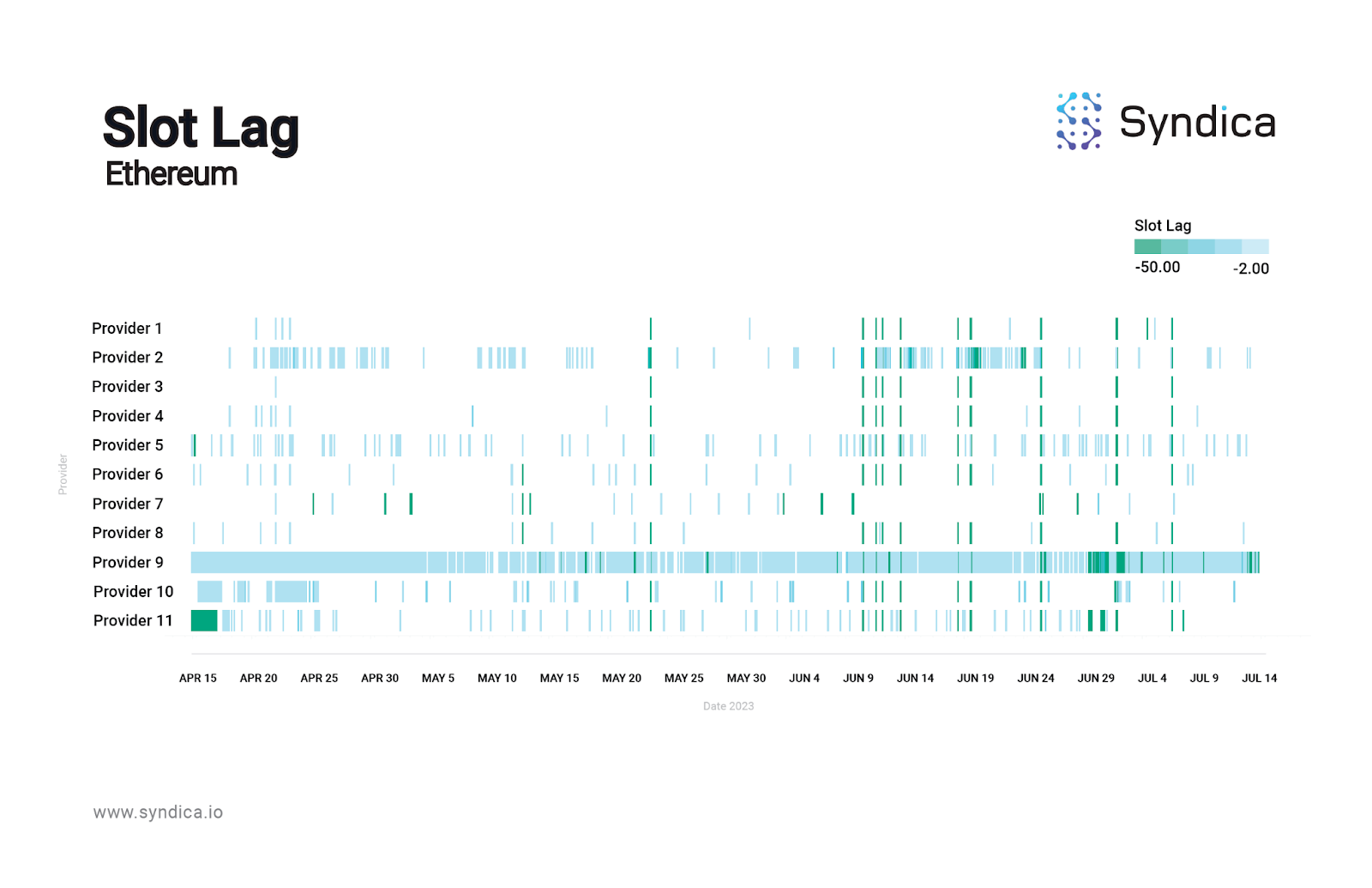
The darker dashed lines represent severe slot lag, peaking at 50 slots or more; Solana’s chart is filled with them whereas Ethereum’s is relatively clear.
User experience on a DApp depends on how well an L1 delivers on expectations. While Ethereum is slower by design compared to Solana (12 second vs. 400 millisecond slot times, respectively), Solana’s speed is stifled by an ecosystem-wide finicky RPC experience.
Solana slot lag is often the result of heavy read calls.
Based on data from a cross-sectional sampling of on-chain programs, Solana nodes are capable of handling just ~60 getProgramAccounts calls per second before degrading in performance (latency spiking, often resulting in slot lag). The thresholds for other ‘heavy’ methods are similar: just 107 getSignaturesforAddress calls, 269 getTransaction calls, and 301 getBlocks calls per second would each degrade a node’s performance. (This makes sense, since these three methods all rely on Google Bigtable, which we’ve observed significantly decreases Max RPS in the case of calls for historical data.)
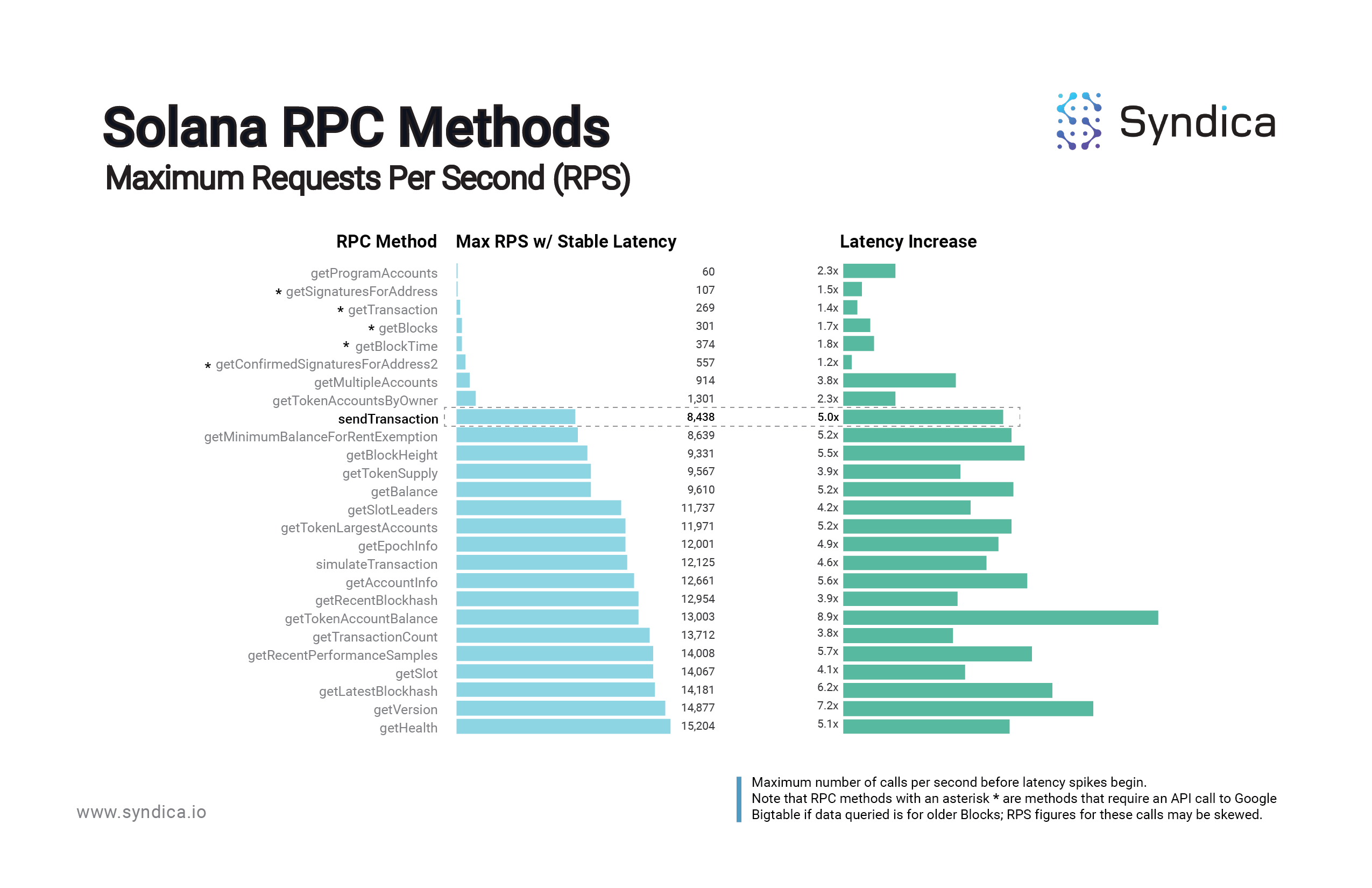
The ‘heavy’ calls tend to be very heavy; for example, a node can handle 250x more getHealth calls per second than getProgramAccounts calls, which makes sense since getProgramAccounts calls are well-known to be extremely taxing calls. Sorting the calls from lightest to heaviest, there is an exponential increase in Load Factor, which is simply a derivative of the RPS metric:
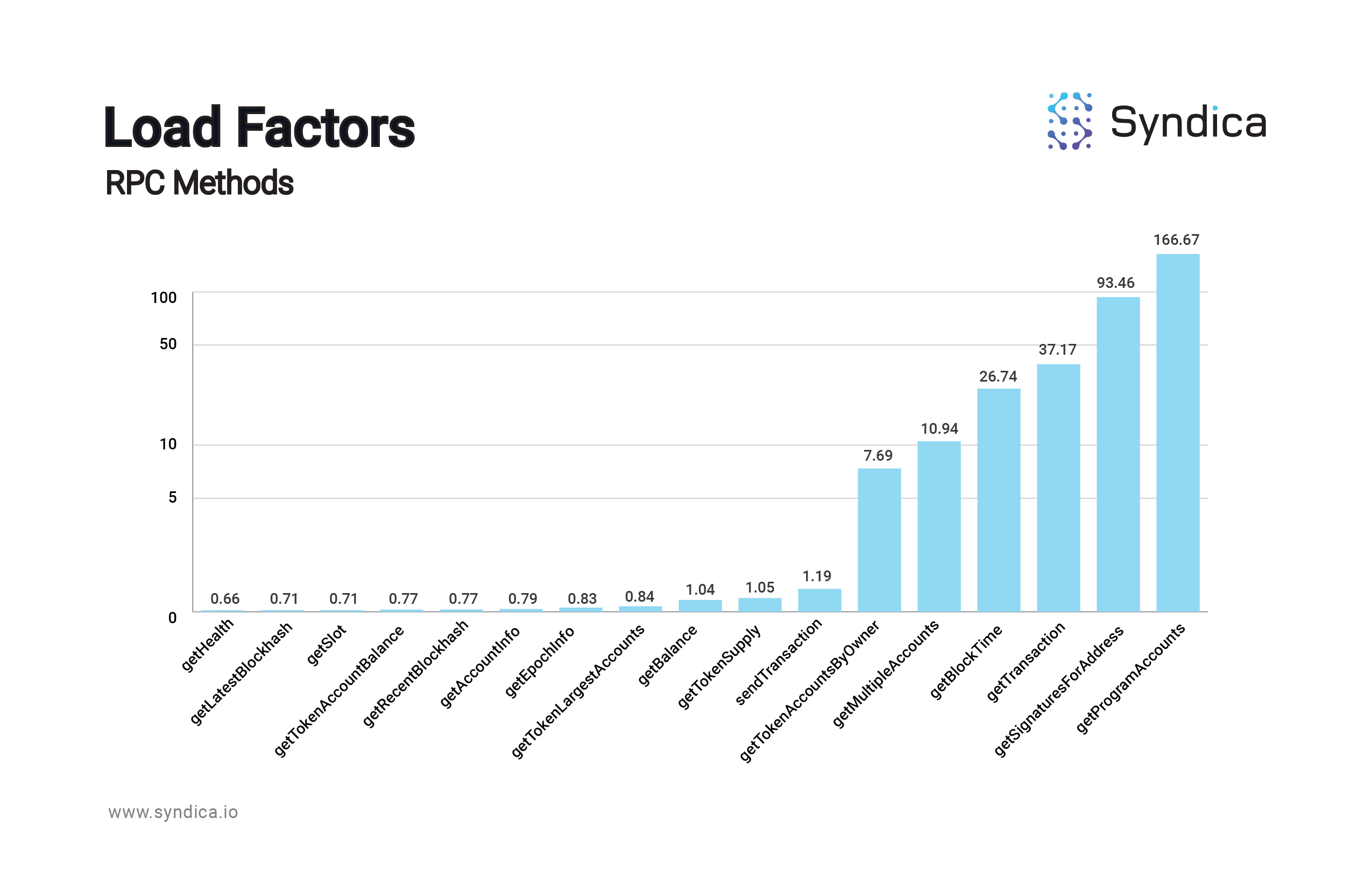
Of course, Solana nodes are stressed by particular method types depending not only on the theoretical weight of the calls, but also on the frequency of their usage:
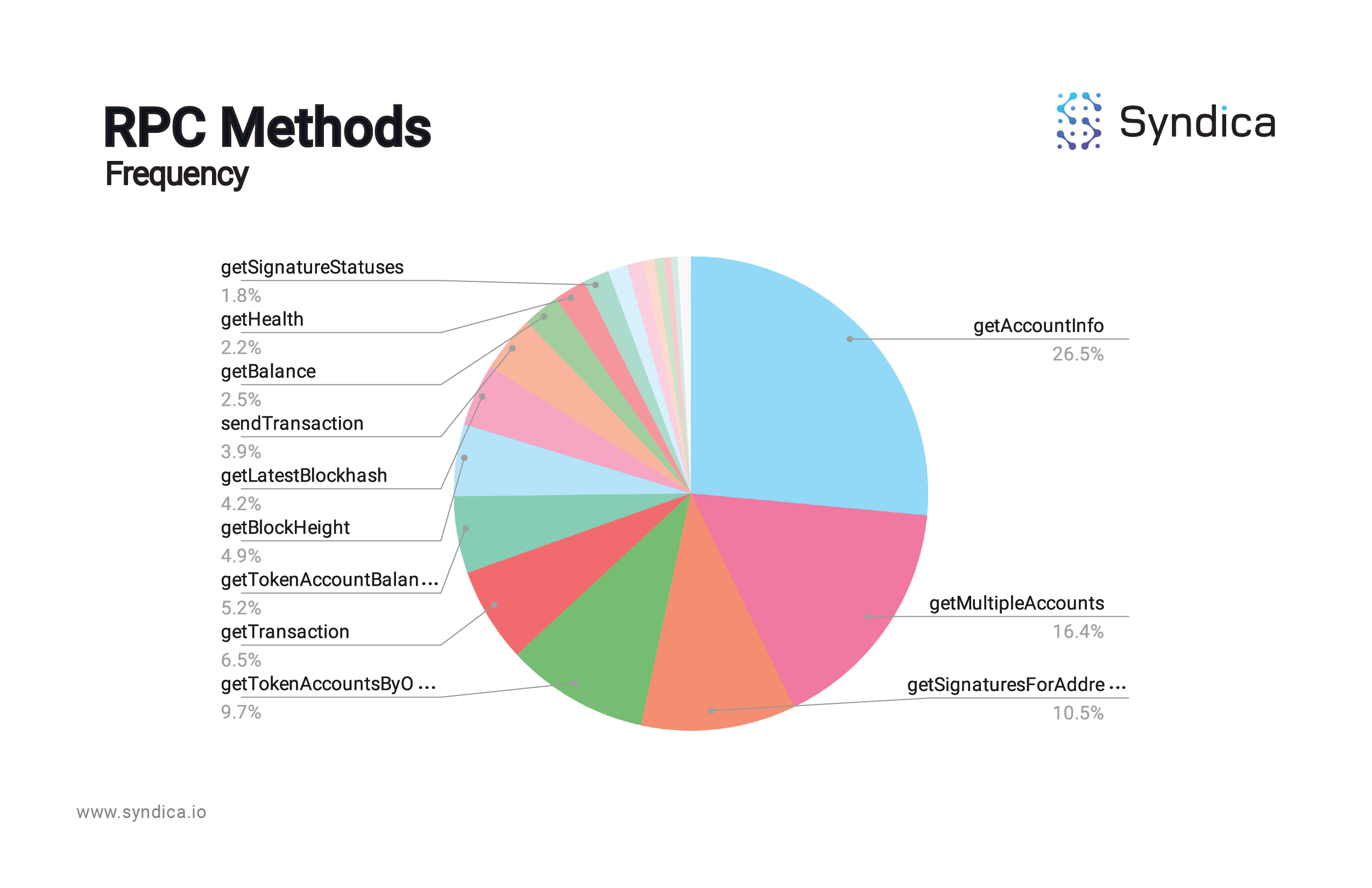
Accounting for the frequency of method usage, a handful of methods fall into a low-RPS, high-frequency range:
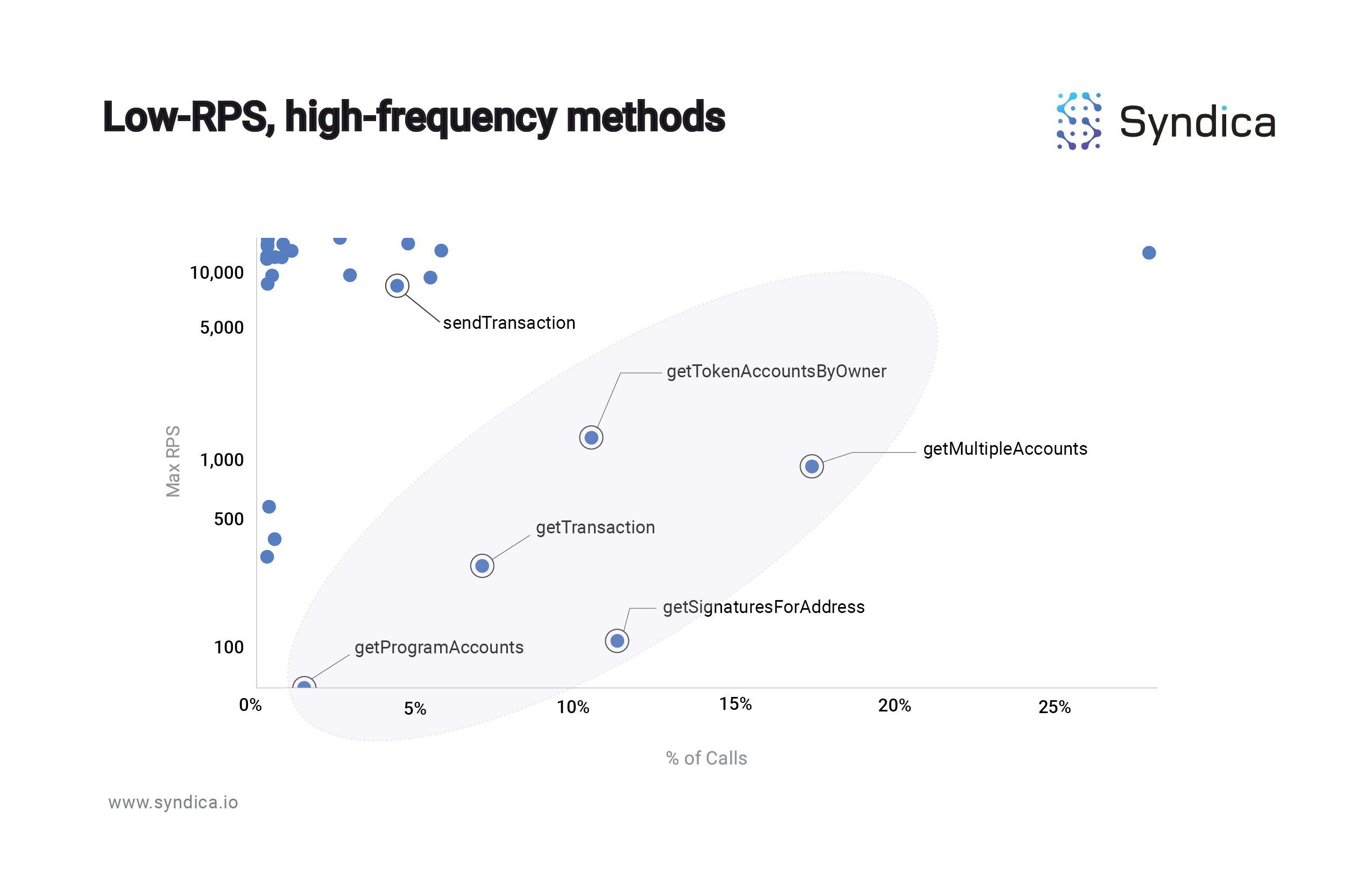
The 5 circled methods - getMultipleAccounts, getTokenAccountsbyOwner, getTransaction, getSignaturesforAddress, and getProgramAccounts - all share the same characteristic: they are frequently used, and they are heavy on the node. Internal data at Syndica suggests that, accounting for the frequency of their usage, these five read methods represent the majority of the “stress” on a typical Solana node. Ideally all methods would fall in the top-left region of the scatter plot; as you look lower and to the right, you encounter the ‘problem’ method region.
Importantly, the only ‘write’ method - sendTransaction - hovers high above the circle since it is, relatively speaking, not as taxing on the Solana nodes. Solving the slot lag issue requires an improvement in the efficiency of reading the chain. In other words, smooth Solana UX requires an increase in RPS.
Sig is a validator implementation that emphasizes maximizing RPS. Validator-level RPC-optimization means lower latencies, lightweight optimized RPC methods, higher throughput, and improved UX.
Sig will improve client diversity and fault-tolerance
As crypto’s most scalable blockchain, Solana plays an important role. Compared to Ethereum, Solana lags in one of the most critical blockchain dimensions: client diversity.
Single points of technical failure
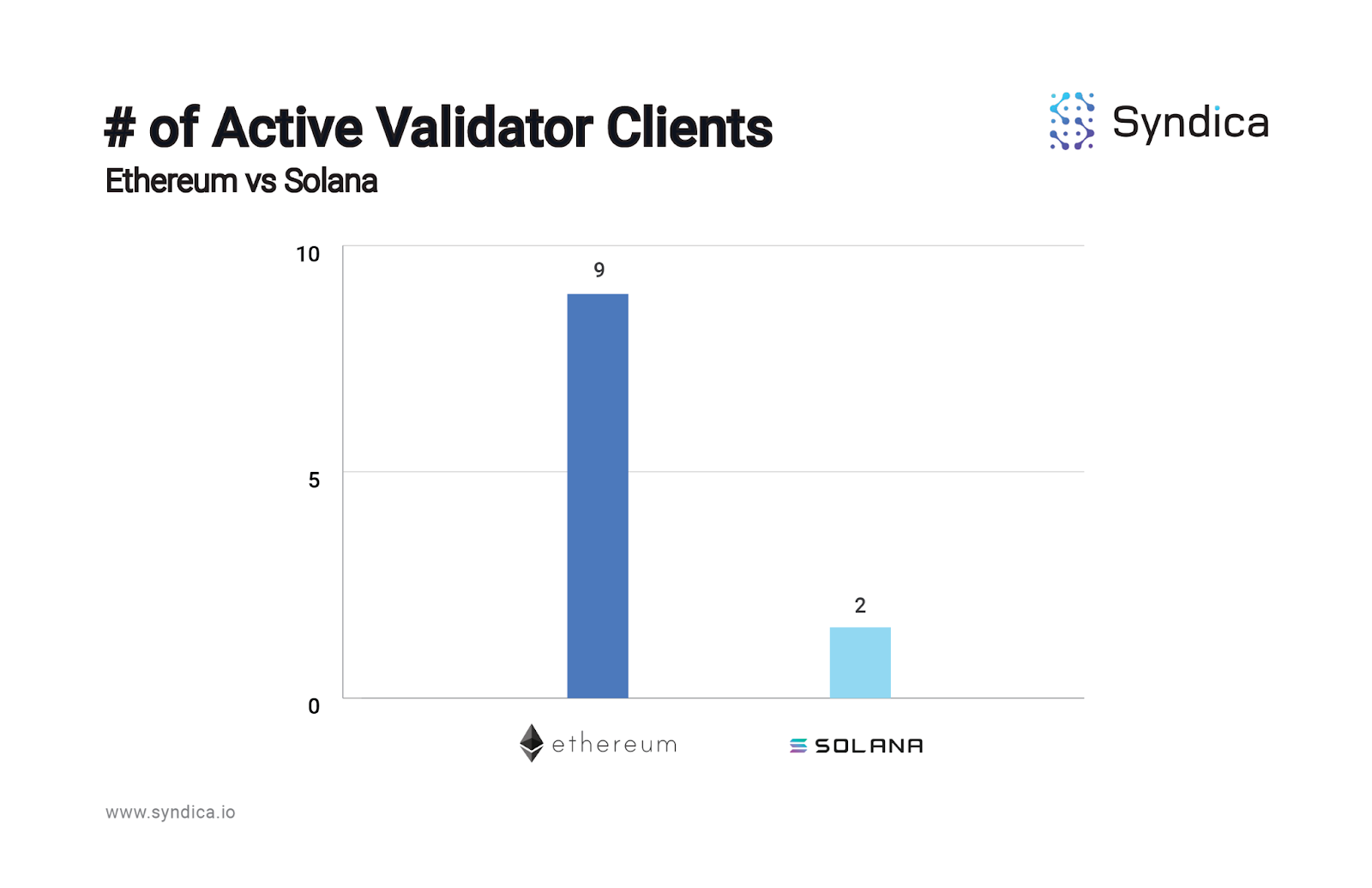
Ethereum boasts 9 independent implementations of its consensus/execution protocols; Solana has just two active validator clients, the second of which - Jito Labs' client - shares some key components with the original.
One of the most critical points of having a diverse number of validator clients is to eliminate single points of failure caused by bugs. This is evidenced by incidents on the Ethereum network. For example, a bug on one of the Ethereum clients in May 2023 caused the client to struggle to process attestations promptly and as a result, blocks were unable to be finalized, as documented in a post-mortem report. Additionally, following a new release, there were reports of increased memory usage in validator clients, leading to out-of-memory errors and subsequent crashes.
These bugs possessed the potential to disrupt the entire network if all users were running the same client. However, thanks to the diverse range of clients throughout the network, stability was maintained. Client diversity is critical to uptime in blockchain networks like Ethereum and Solana.
“Validator client diversity is important beyond providing protection from zero-day exploitation. If a bug exists in one client, it’s highly unlikely that it exists in other clients. That means that a bug in a single client is much less likely to cause a long network outage, especially if multiple clients are being used at high rates.”
Solana Foundation, March 2023
Language diversity

While Ethereum’s validator has been implemented in seven languages, the Solana validator has been implemented in just Rust and, soon, C (Jump's FireDancer) and Go (Jump's Radiance).
“The foundation of a client in a particular language opens and invites experimentation and innovation in that language. The base tooling around the client often snowballs into a robust ecosystem of tools and contributors in that language.”
Ethereum Foundation Researcher Danny Ryan
Sig will offer unprecedented accessibility
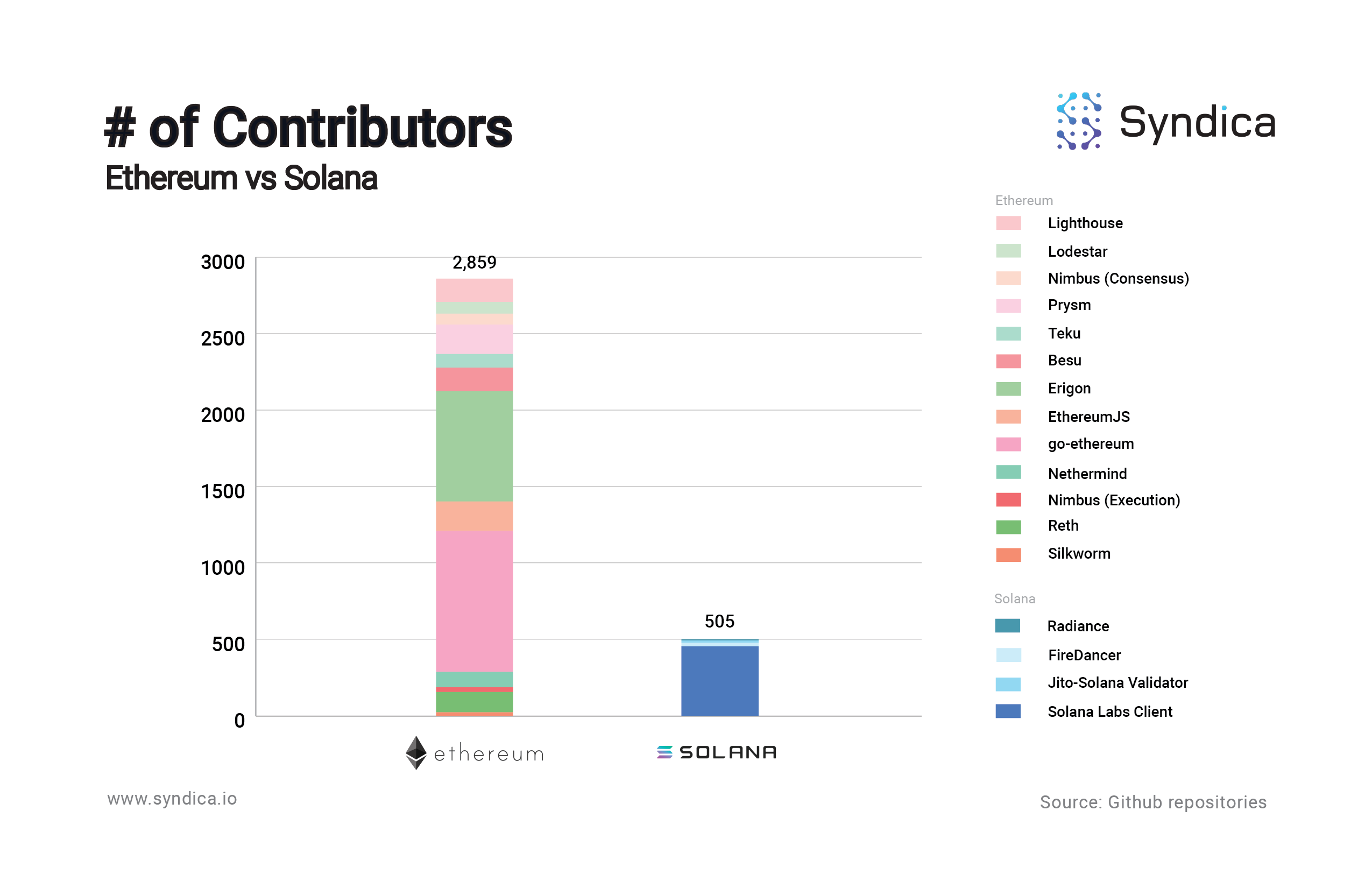
Solana has less than a fifth of the number of contributors of Ethereum. Many in the Solana developer community feel that the Solana repository is difficult to read, understand, and contribute to. This makes sense - the Solana (Rust) implementation was the initial implementation and therefore suffers from years of bloat and backwards-compatibility patches that understandably led to less-than-ideal design decisions.
One way to approximate a codebase’s complexity is by the number of lines of code (LOC), specifically looking at the largest files in the codebase since the largest files make up a disproportionate percentage of the entire codebase. For example, the top 1% largest Solana validator files comprise 20% of the total lines of code, and the top 10% largest comprise 58% of the total lines of code.
Charting the largest files (top 1%) in the most popular Ethereum validator clients and Solana’s, the Solana (Rust) codebase is markedly more verbose:
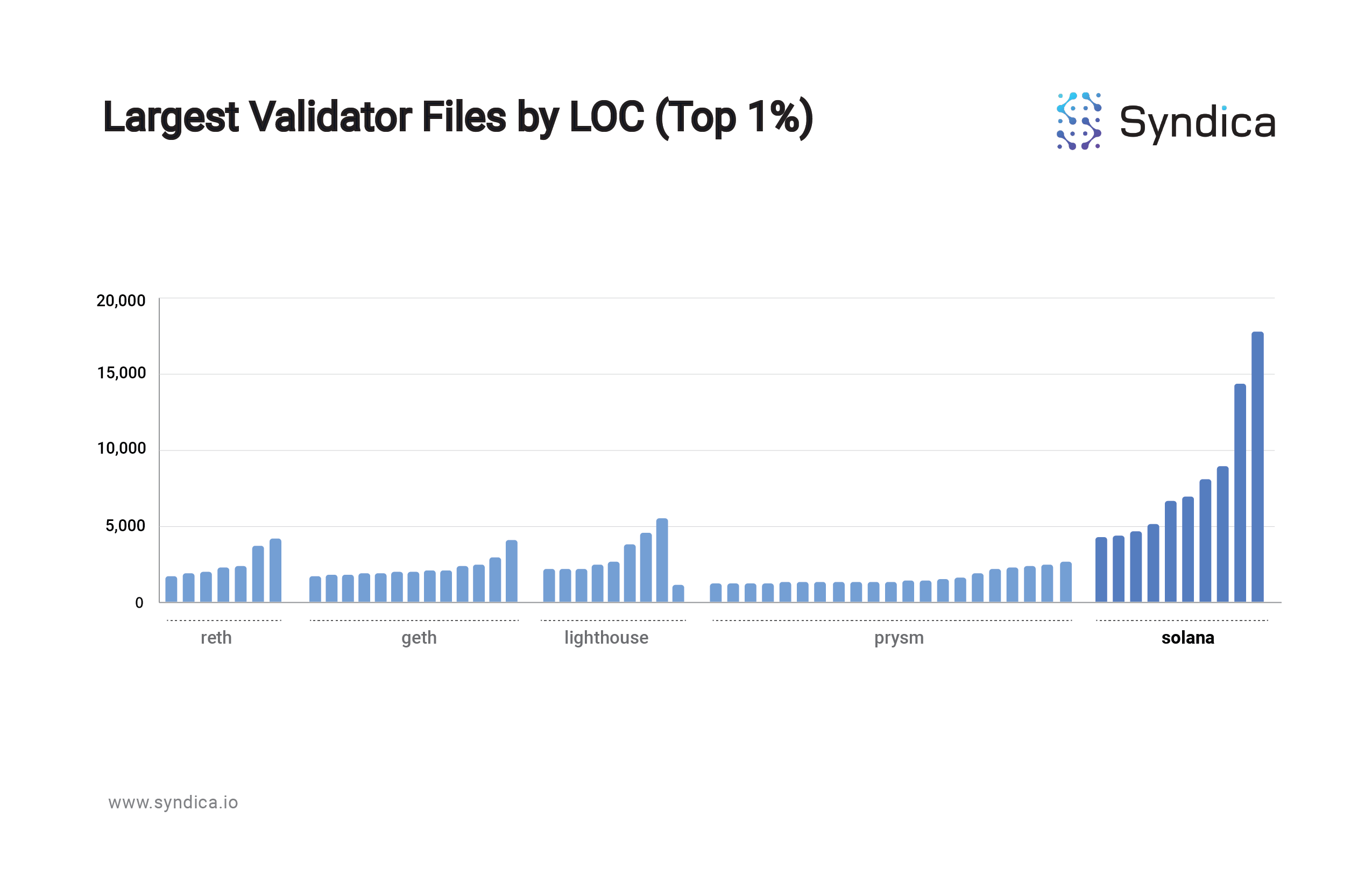
Sig is focused on readability and simplicity because accessibility is a validator client’s most underrated feature. Innovation, protocol maintenance/observability and developer tool-set creation require a modular and contributor-friendly implementation of the protocol.
Sig will offer the first simple-to-read implementation of the Solana validator client, which will allow others to build upon it and contribute back to the community.
Technical Implementation
Zig's Traction
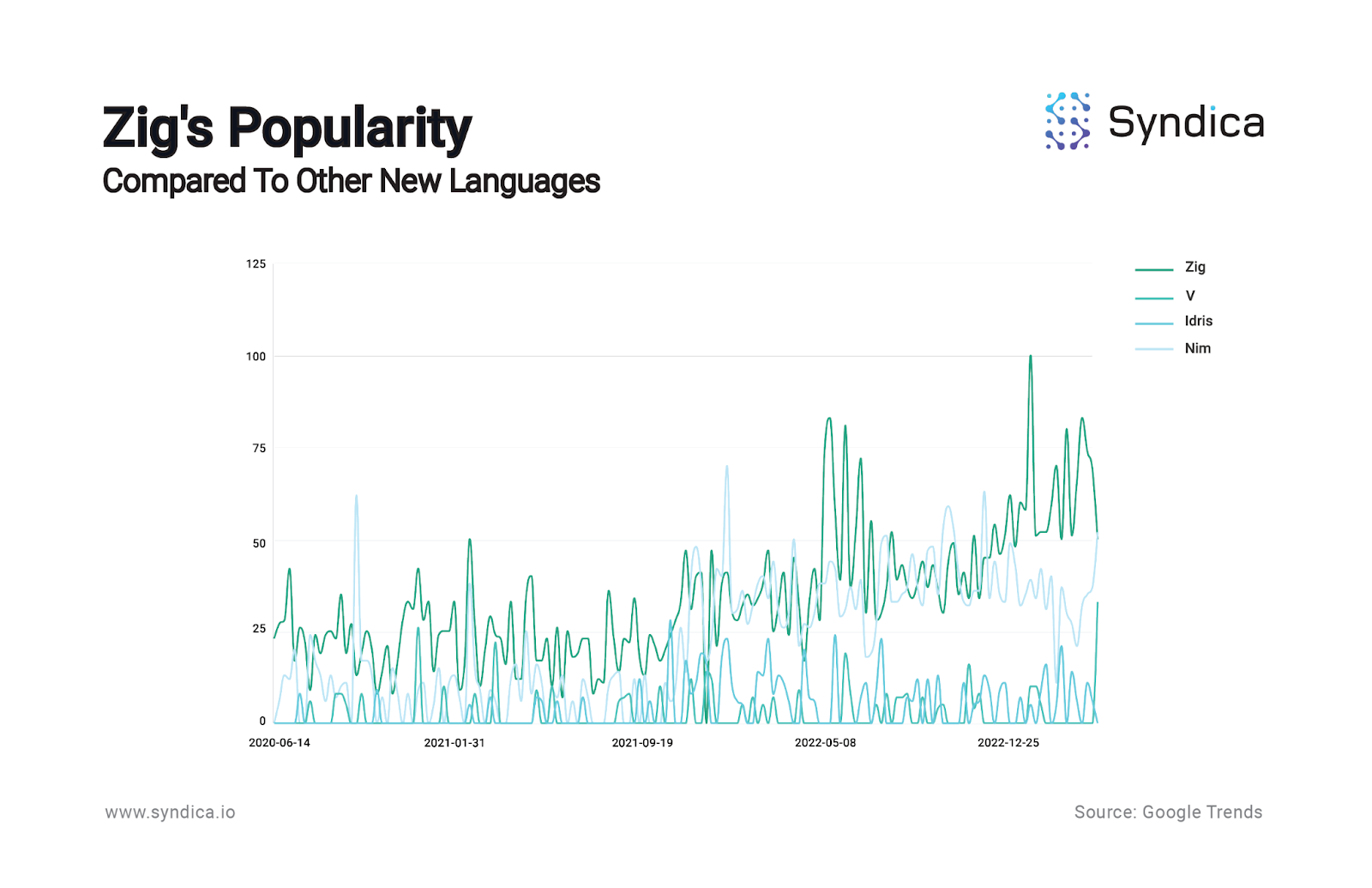
Zig has achieved significant traction with a robust developer community.
Zig has grown in popularity compared to other new languages. Here’s a Google Trends breakdown comparing Zig to other similar recently released programming languages, with Zig as the dark green line:
Moreover, despite being a very early language without a v1 release, Zig has attracted some big companies like Uber, AWS, and CloudFlare, which use a Zig toolchain. Uber uses bazel-zig-cc for their cross compilations and startups like Oven, which develops software development tools and TigerBeetle, a financial accounting database, use Zig as their primary coding language. Other companies that use Zig include HexOps, Cyber, and Extism.
Lastly, Zig's Github commit activity shows steady progression:
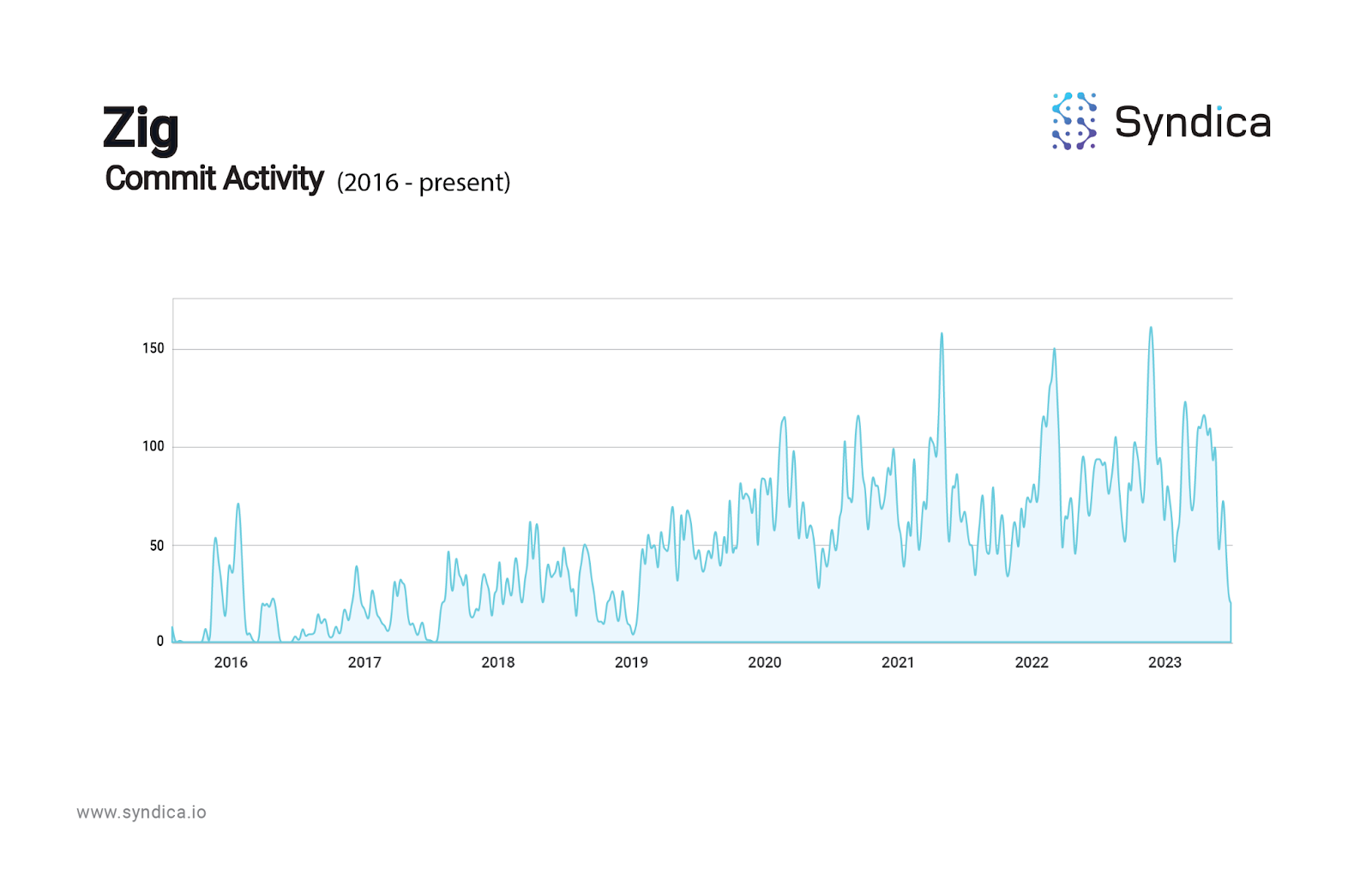
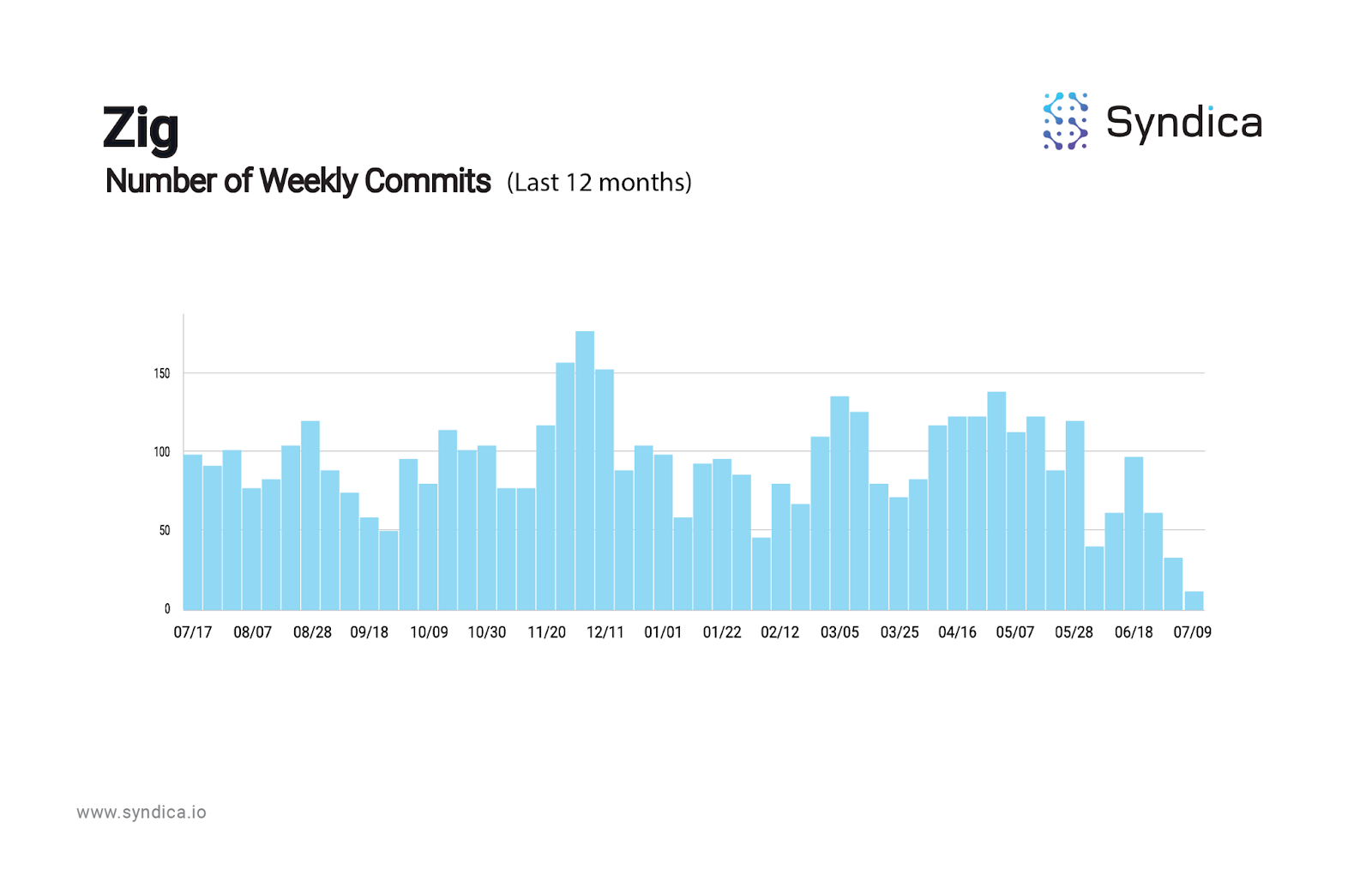

Using Zig's Technical Advantages
The Zig Software Foundation describes Zig as a “general-purpose programming language and toolchain for maintaining robust, optimal and reusable software.” It provides a healthy balance between simplicity, language features and readability without sacrificing performance, which is precisely what’s needed in a deeply hardware-optimized validator client implementation.
Zig offers simplicity without sacrificing power. It has a low barrier to entry and any developer with C, C++, Rust or even Go experience can get up and running with Zig with little effort. Its lack of hidden control flow makes it easy to understand and digest even larger codebases.
The language provides the capability to use custom allocators, which are user-defined specifications that govern how your program will allocate and deallocate memory. This is especially useful when you have parts of your program that allocate to the heap often, allowing you to use something like an Arena Allocator for better performance. Coupled with explicit allocations, a feature that requires programmers to consciously allocate and deallocate memory, Zig offers us a high degree of control over memory usage, an essential aspect of resource management and critical for hardware-optimized distributed systems.
Zig delivers performance on par with C, the most efficient low-level language. Zig also features interoperability with C and C++, allowing direct inclusion of C or C++ libraries. This eliminates the need for any wrappers or bindings, simplifying the incorporation of existing C or C++ code.
Zig introduces 'comp-time', a functionality that allows certain parts of the code to execute at compile time. This capability is particularly useful for moving potential runtime computations to compile time, thereby reducing the computational load during runtime and leading to more efficient programs along with easy meta programming without the direct need for generics or interfaces. Without effective compile-time meta-programming, one must resort to macros or codegen, or worse, do a lot of useless work at runtime.
Zig enables implementation of several performance-focused features which will power improved RPS.
Zigs General C interoperability:
A powerful aspect of Zig is its seamless interoperability with all C code. This interoperability allows us to tap into a vast ecosystem of C libraries, frameworks, and tools, benefiting from their optimized implementations. By combining Zig's modern language features with the performance optimizations of existing C code, you get the best of both worlds and can achieve high-performance with modern programming language features such as explicit error handling, expressive return types, and more, which leads to fewer errors/bugs in the code, an easier-to-understand codebase, improved maintainability, and enhanced developer productivity.
For example, below is a Zig code snippet that demonstrates the seamless integration of Zig and C code, leveraging the high-performance system calls recvmmsg and sendmmsg to efficiently handle multiple messages in a single system call:
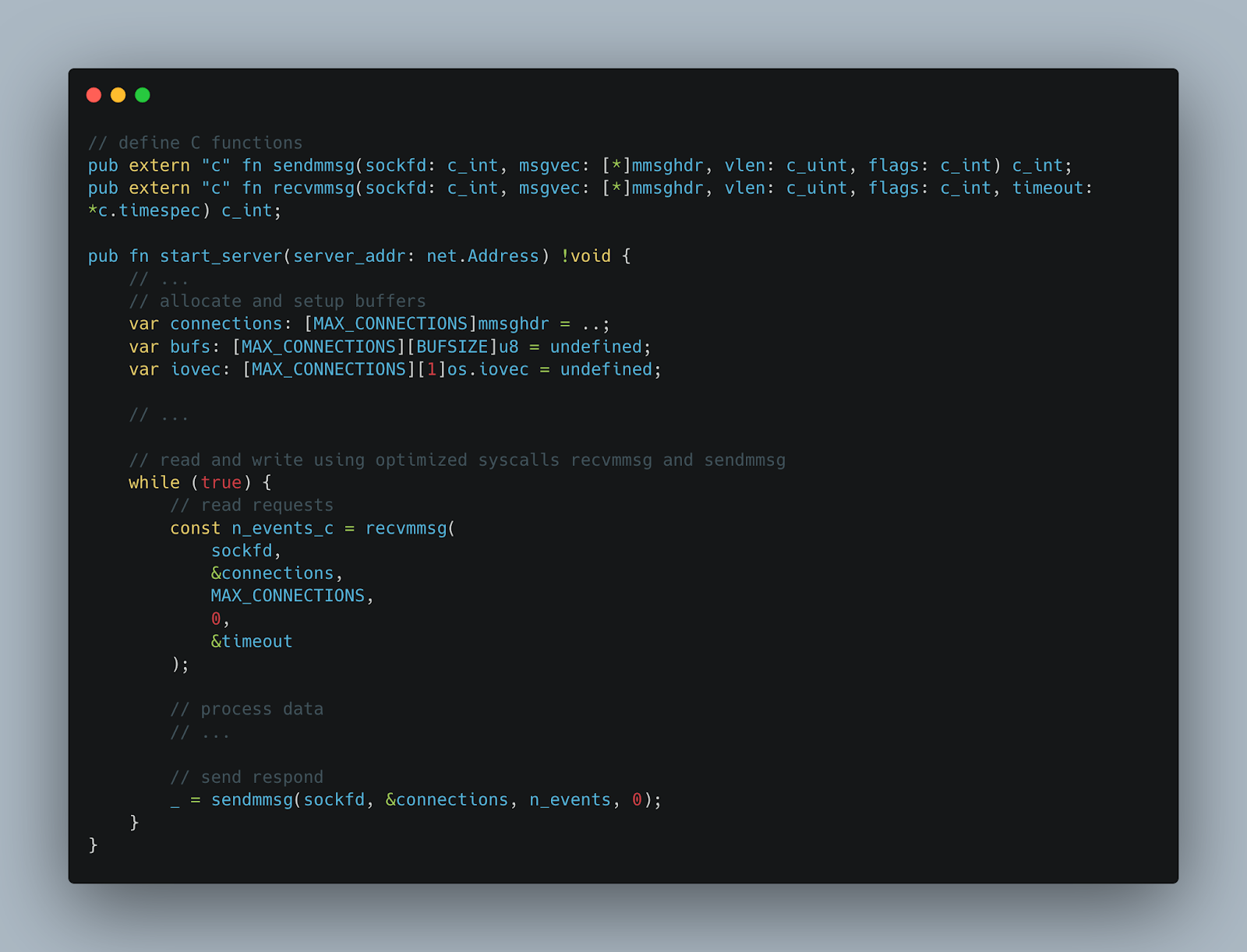
Zig gives developers the ability to write clear, concise code that is maintainable and extensible in the long run and provides a reader with a general understanding of what the code is trying to accomplish at first glance. This is an important feature that will be helpful especially to the Solana community, and will allow them to continue to innovate, improve and contribute back to the ecosystem.
Additional Optimizations
A few additional optimization methods we plan to investigate include: io_uring for efficient file system I/O and eBPF XDP for high-performance network packet processing.
io_uring for file system I/O:
Zig allows us to make use of io_uring for zero-syscall filesystem I/O to optimize the Bank and Blockstore data structures for faster async read/write operations. Using io_uring we can deliver faster access to critical data which will lead to improved RPS.
eBPF XDP for networking:
We plan to use eBPF XDP (extended Berkeley Packet Filter eXpress Data Path) to process network packets more efficiently. Standard network packet processing involves making expensive system calls to the kernel to read packets into the program. XDP will enable packet filtering and manipulation directly within the Linux kernel, eliminating the need for packets to traverse the entire networking stack, significantly reducing latency and overhead.
Sig's first component: Gossip protocol
We’re starting development of Sig by tackling one of the most important core components of any blockchain: the gossip protocol. A gossip protocol propagates data to nodes across a network efficiently. It is a core component of a distributed system. Below is a preview of Sig's gossip in action:
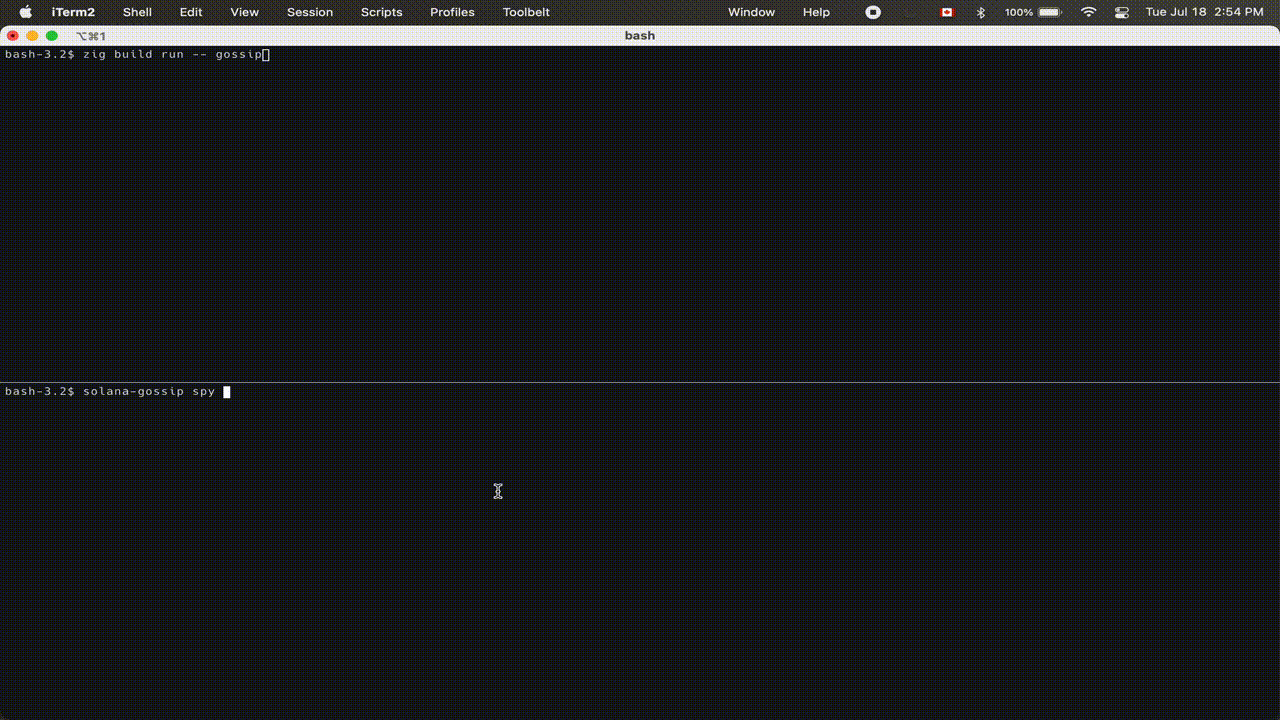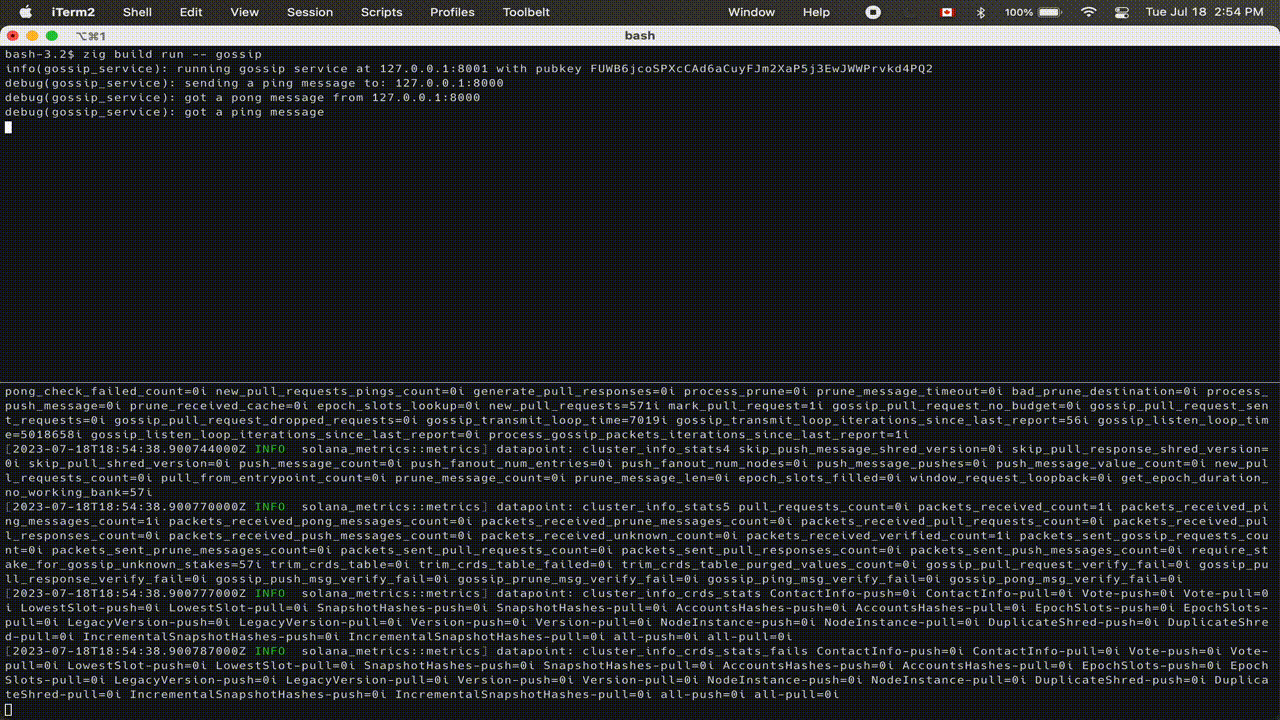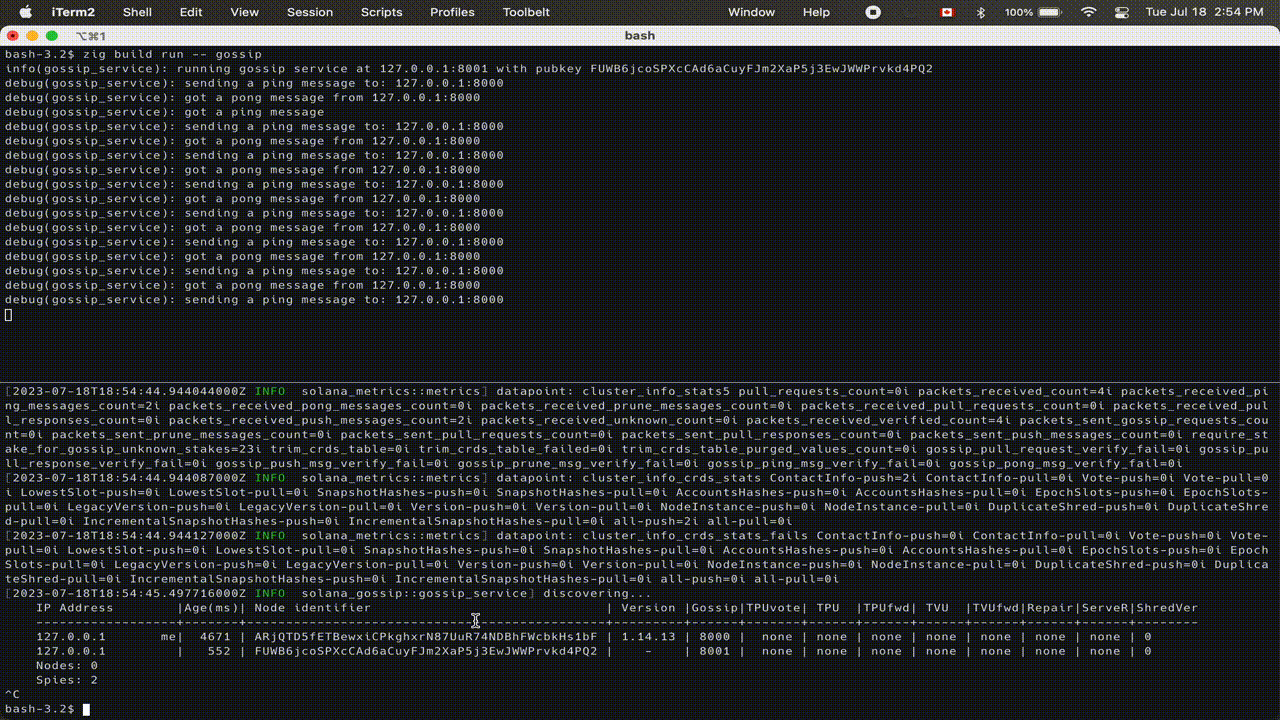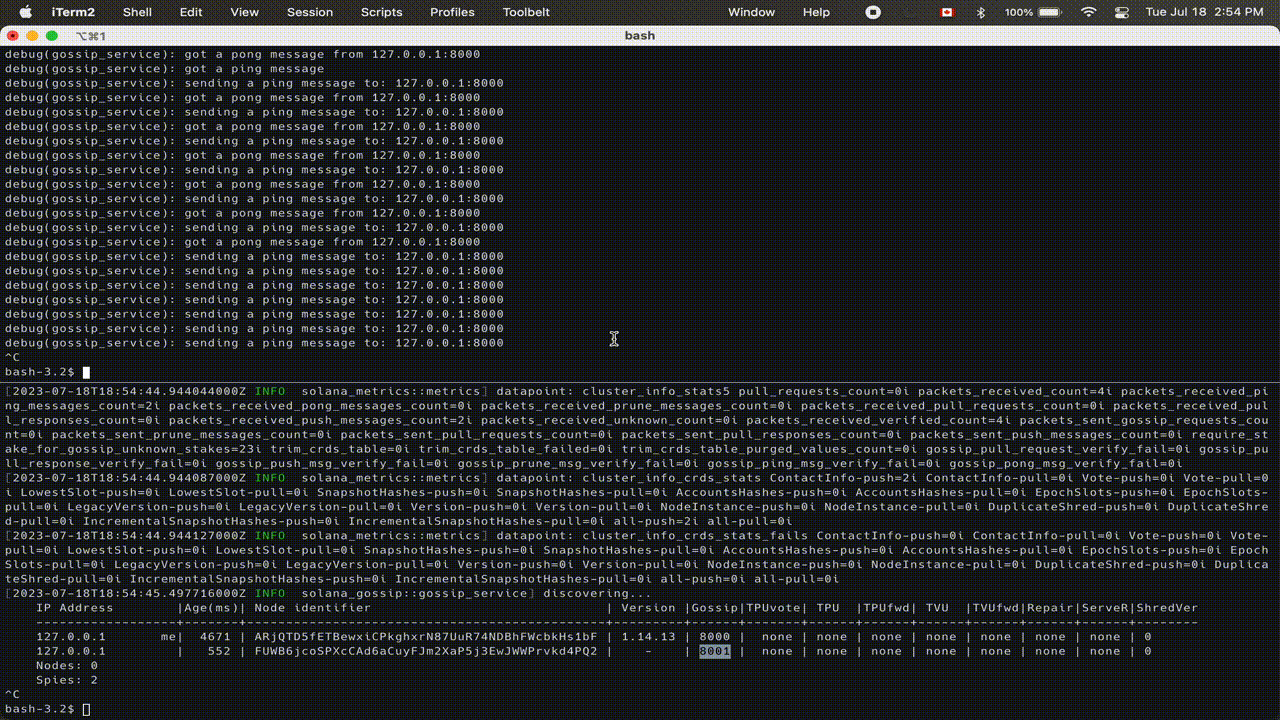
We are tackling gossip first because it is a node’s entrypoint to the network, allowing it to identify other nodes in the network and to receive and sync metadata about the state of the blockchain. Solana’s gossip protocol is also isolated from other components of the validator such as block propagation (Turbine), runtime (Sealevel), consensus (Tower BFT), etc. This allows us to quickly build some of the core primitives/modules needed for a full client such as the serialization/deserialization framework, data structures that need to be replicated across client implementations, a robust testing framework, and a durable build pipeline.
How Gossip Works
A straightforward way to share data across a network is to broadcast the data to all the nodes on the network. However, when the network includes a large number of nodes, this concentrates a large amount of work on a single node, which is undesirable. To fix this, messages can be broadcast to a subset of nodes, who then broadcast the message to the rest of the network, similar to a tree. Below is a diagram of the two approaches.
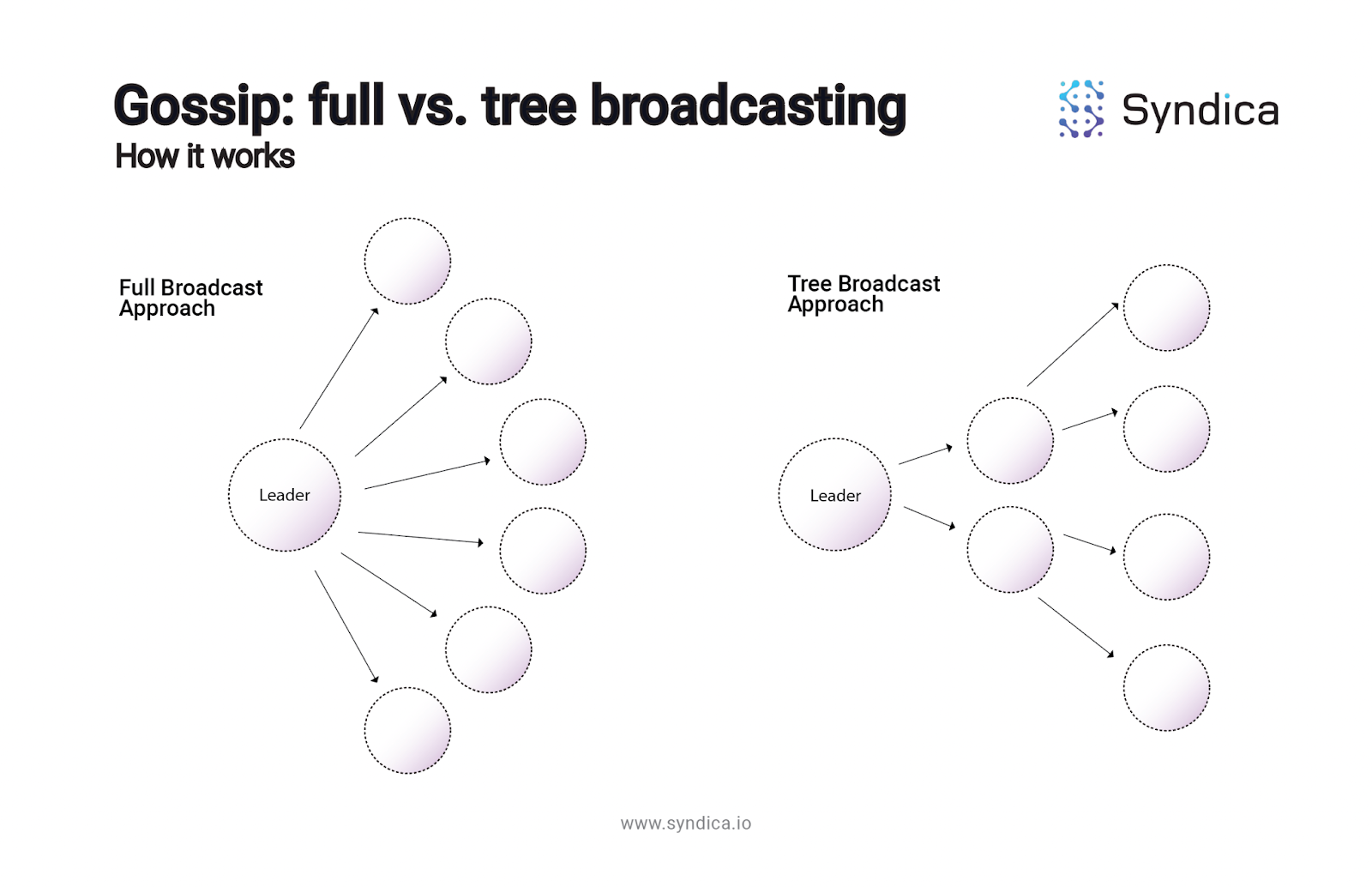
Solana’s gossip protocol uses the tree broadcast approach and is based on the PlumTree algorithm, with a few modifications. To understand how Solana’s gossip works, it’s useful to understand how PlumTree works first.
PlumTree Explained
The general idea of the PlumTree algorithm is to send the full message to a subset of nodes - known as the ‘active set’ - and send the hash of the message to all the other nodes.
The hash message is a data-efficient way to inform the other nodes that they should receive the full message soon. If a node doesn’t receive the full message in some amount of time, they use the message’s hash to request the full message from another node, and both nodes add each other to their active sets (forming a new link in the tree for data propagation). This process ensures all nodes receive the full message by fixing broken data propagation paths in the network.
When a node receives a new full message, it then forwards the message to its active set - propagating the data to the rest of the network. When a node receives a full message that they’ve already received previously they send a prune message to the sending node who then removes the node from its active set (essentially, removing a branch from the tree).
This algorithm forms an efficient tree-structure for data propagation across the network.
How Solana improves on PlumTree
In order to have this algorithm work in a setting where nodes could be adversarial, Solana makes a few changes to this algorithm. This includes defining five message types: Push, Prune, Pull, Ping, and Pong.
Similar to PlumTree, Push messages are used to propagate data across the network using the node’s active set. And Prune messages are sent when duplicate Push messages are received to reduce redundant data propagation.
Pull messages are used to ensure that all nodes have consistent data (in case data is lost in the Push messages). Pull messages are sent periodically to a random set of nodes and include a bloom filter which represents the data that the node currently has. When receiving a Pull message, the node searches and responds with gossip data that was not included in the bloom filter.
Lastly, Ping/Pong messages are used to check if a node is still active or not. Specifically, a node periodically pings other nodes and expects a corresponding Pong response. If a pong is not received, the node is assumed to be inactive and is no longer sent Push/Pull messages.
Solana Gossip Data
Two important data types that the gossip protocol propagates are the ContactInfo and Vote data structures.
The Contact Information structure is the entrypoint to the network and is used to discover and communicate with the other nodes. It includes information about which ports correspond to specific tasks (including block/vote propagation ports, RPC ports, repair ports, etc.). The Vote structure is a part of Solana’s consensus protocol and represents a node confirming that a specific block is valid.
A working Gossip implementation is crucial for the node as it enables communication with other nodes in the network and facilitates the construction of a chain of valid blocks. Our first step to implementing Sig, therefore, is a working Gossip implementation.
Additional information on Gossip can be found here: https://docs.solana.com/validator/gossip
What’s next?
A high-level overview of components that we will be implementing:
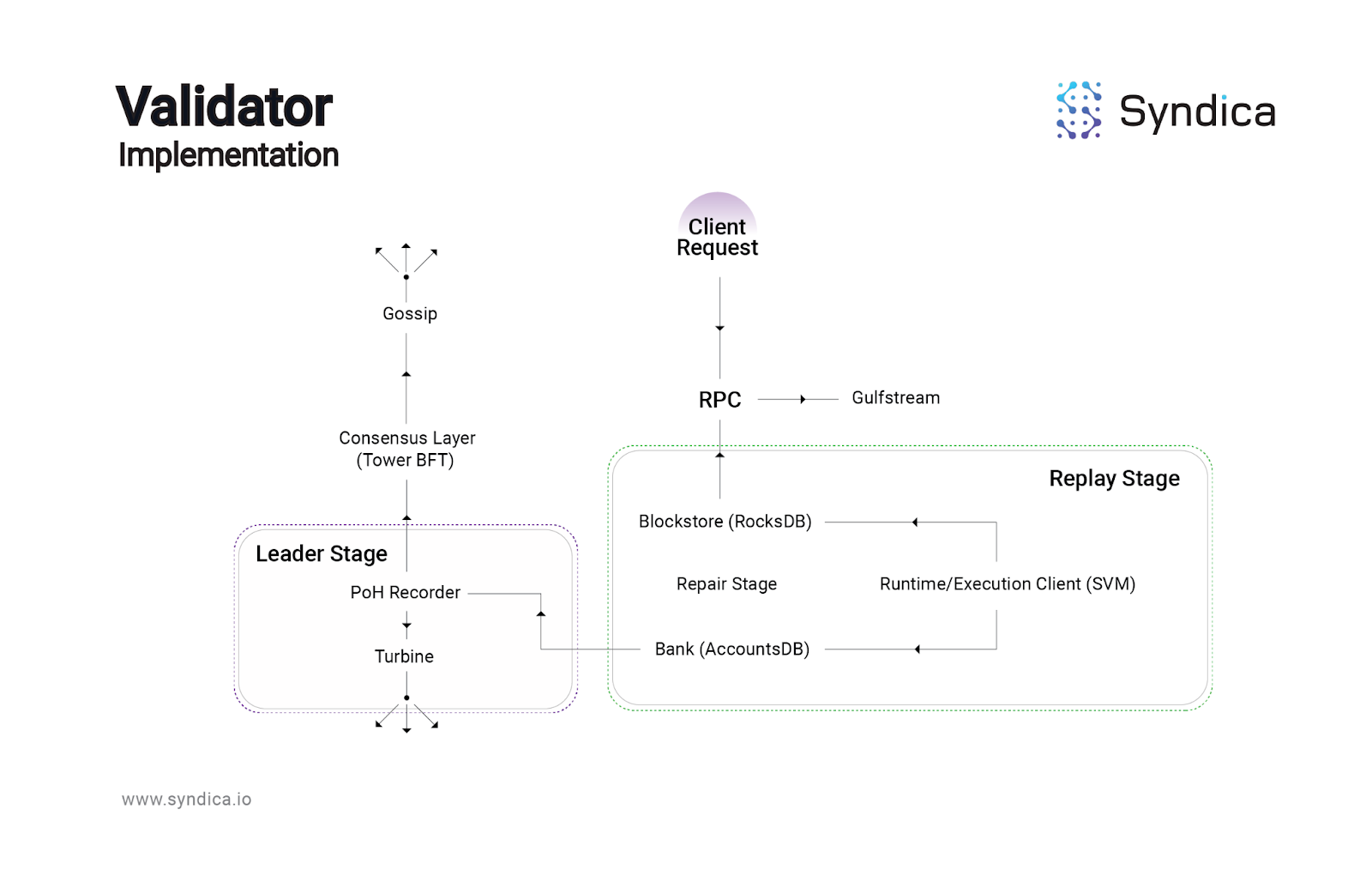
Syndica aims to rewrite the following components of the validator implementation:
- Gossip
- Replay Stage
BlockStore (RocksDB)
Bank (accounts and states) - AccountsDB
Runtime/Execution client (Sealevel & SVM)
Repair stage (to fix missing shreds) - Consensus layer (Tower BFT)
- RPC
- Gulfstream (Transaction forwarding)
- Leader Stage
PoH Recorder
Turbine (Block Propagation)
Gossip: the entrypoint of the network where nodes discover other nodes, sharing metadata about their setup and the chain including what ports are open, vote information, and more.
Replay Stage: responsible for replaying new blocks received from the leader, reconstructing the state of the chain throughout time, and requires multiple other components including the BlockStore, the Bank, the Runtime/Execution client, and the Repair stage.
Blockstore: a database which stores blockchain metadata including shreds, transactions, slot information, etc.
Bank: a highly-optimized database to represent the state of the blockchain at a specific slot, including the state of all the accounts.
Runtime/Execution Client: the Solana Virtual Machine (SVM), which is an execution environment that updates on-chain accounts by processing transactions with on-chain programs. This includes Sealevel, which processes batches of transactions in parallel.
Repair Stage: responsible for fetching missing shreds from other nodes.
Consensus Layer: this includes the TowerBFT protocol and is used to find the most up-to-date state of the chain by tracking validator votes of which blocks are valid. This layer is also responsible for handling forks in the network.
RPC: responsible for serving on-chain data to other clients using remote-procedure calls including account balances, transaction statuses, and more.
GulfStream: Since Solana does not have a mempool, Gulfstream is responsible for sending transactions directly to the upcoming leaders. This requires knowing validator stake amounts to be able to reconstruct the leader schedule.
Leader Stage: With the above components, the node can join the network, vote on valid blocks, and serve on-chain data to clients; however, to construct new blocks it needs a few more components including Proof-of-History and Turbine.
Proof-of-History (PoH): PoH records a proof of the passage of time using a self-hashing loop and is required when constructing new blocks.
Turbine: Once a new block is constructed, it is then propagated through the network using Solana’s Turbine protocol which is similar to a tree-like broadcast structure.
Stay up-to-date:
Follow our dedicated Sig Twitter for updates: https://twitter.com/sig_client
Join the discussion on Discord: https://discord.com/invite/XYdHaetwdd
Follow our Github repo: https://github.com/Syndica/sig
Join Our Team
We are excited to build Sig and are looking for Senior Engineers to help contribute to the future of Solana!
As a member of our team, you will play a pivotal role in designing and implementing a high-performance Solana validator client from scratch. If you are a talented engineer who thrives in a collaborative and fast-paced environment, and you're excited about contributing to the advancement of Solana's ecosystem, we would love to hear from you.
Interested candidates can apply here.


