Sig Engineering - Part 7 - AccountsDB & Gossip Memory Optimizations

This post is Part 7 of a multi-part blog post series we will periodically release to outline Sig's engineering updates. You can find other Sig engineering articles here.
This blog post details recent optimizations made to existing Sig components, including a new buffer pool implementation for AccountsDB and a new Gossip Table backend that greatly reduces Gossip’s memory footprint.
AccountsDB - New Buffer Pool
AccountsDB is Solana’s account database, which maps public key addresses to onchain accounts. We recently redesigned AccountsDB’s memory management by implementing a new buffer pool from scratch. This section will explain why we made this change and the benefits we gained.
Solana’s total number of accounts is quickly approaching the billions, requiring hundreds of gigabytes of storage. Most of these accounts are stored on disk in “account files,” making disk I/O one of the main areas of optimization.
Note: For more about AccountsDB, see our blog post about AccountsDB here.
How mmap works
Originally, Sig used the mmap syscall to read the account data from these files. mmap tells Linux’s memory management subsystem to create a new Virtual Memory Area (VMA), which is a contiguous range of virtual memory space. Virtual memory and physical memory are made up of blocks called “pages,” which are typically 4 KiB. A VMA can span many pages of virtual memory and holds important metadata for its memory region, such as page protections. We used mmap to create a read-only VMA for each account file on disk that we wanted to access in AccountsDB.
One benefit of using mmap in this way is that it allows us to write code as if all the files are entirely in memory. Unfortunately, it’s more complex than this. When we read data from one of these files, we will likely get a “page fault.” A page fault is an exception raised by the Memory Management Unit (MMU) when an accessed virtual memory address has no corresponding page in physical memory. Here’s a diagram of how a page fault occurs under these conditions:
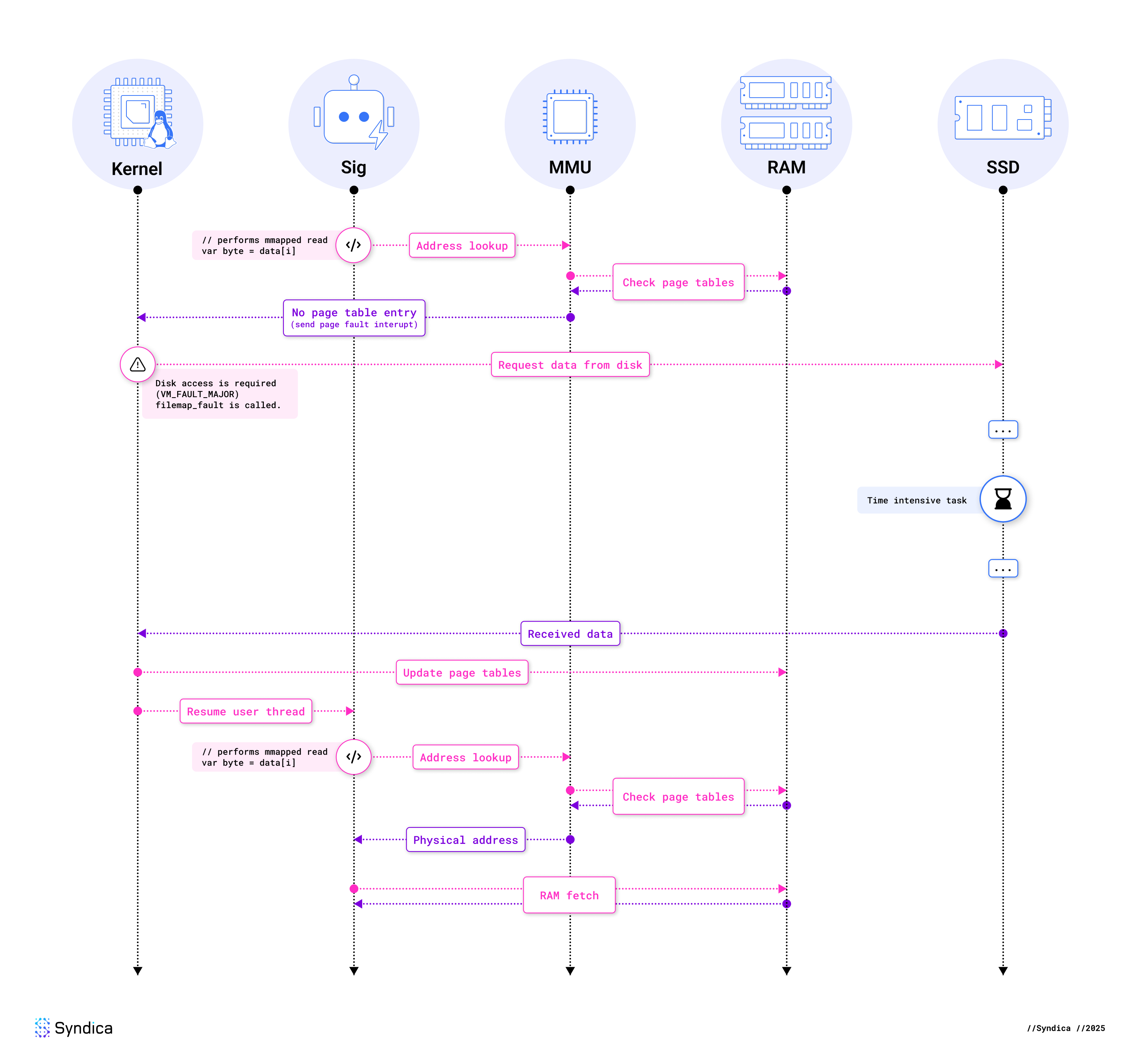
Note: We’ve glossed over some parts of the CPU, such as the TLB and caches, for simplicity’s sake. However, in the context of a page fault requiring the disk, these details aren’t relevant as they would also be highly architecture-dependent.
As you can see, it is the kernel’s job to resolve the page fault. To read from the disk, the kernel allocates a new page of physical memory and fills it with data from the disk. The kernel then maps from the virtual memory page to this new physical page inside its page tables.
Of course, the implementation is much more involved than this. Here’s a summary of what the Linux kernel is doing behind the scenes:
handle_mm_faultis called, starting the (non-architecture-specific) page fault handling.- As our mapping is read-only, the kernel eventually calls
do_read_fault. - When we called
mmap, we did it with a file, which means that the VMA’s metadata includes function pointers provided by our file system. Now that we’re faulting,vma→vm_ops→faultis called, which, in our case, was set byext4_file_mmap. - This function for a typical file system will be
filemap_fault, where the kernel interacts with its page caching subsystem. If the page is not in the page cache, this is considered a major page fault. - It then calls
page_cache_ra_unbounded(“ra” for readahead), which eagerly reads files into the page cache. In most cases, the kernel will read more data from the disk than is required to resolve the current page fault, assuming the application will read the extra data soon. To read ahead, this function allocates pages, potentially causing page eviction, and adds them to the kernel’s file map. - When data isn’t in the file map,
read_pageswill be called, which submits batches of IO and calls into the filesystem. - Once the data is all present,
finish_faultupdates the page tables. - When the above steps are complete, the user-mode thread may be resumed.
In summary, access to a file-backed memory-mapped region causes page faults, which can perform blocking disk IO via the page cache.
Disadvantages of mmap for IO
While mmap helped us quickly develop AccountsDB, there are a lot of non-obvious faults with its usage for IO over other syscalls.
High Memory Usage and Pressure
One of the most significant issues in the context of a Solana validator is the increased memory usage associated with using mmap. The Linux Kernel uses its page cache to optimize accesses: when a single page fault occurs, the kernel reads some pages before and after it into the page cache. This helps performance in sequential reads, as fewer page faults cause blocking on disk IO later. However, not only is this not helpful for random reads (our primary use case), but it also wastes a lot of memory and multiplies the amount of disk IO we’re doing. These pages are not marked as “used” memory in the usual sense, as they’re up for eviction whenever. Easily reclaimable memory doesn’t sound too harmful, except it greatly increases memory pressure system-wide and can even cause a Linux system with a lot of available memory to start using swap.
No Control Over Eviction
As previously mentioned, the kernel can evict pages owned by the page cache at almost any time—they are reclaimable. While it is convenient to have this handled for you, it is not ideal for any database; Linux has some coarse data on page accesses, but controlling page eviction in the application allows us to make smarter decisions.
No Non-blocking API
On a fault (and a page cache miss), the kernel performs blocking disk IO in an entirely opaque way to the faulting process. This means that the blocking IO firmly blocks the thread that accesses the mapped data; a better approach would allow us to do useful work while waiting for the disk, but mmap does not have an asynchronous API. Even with modern drives, waiting for a disk read can cost hundreds of microseconds; threads that read a lot of mapped data can spend most of their time spinning on IO.
Hidden Blocking Costs
As we have little control over the kernel’s page faulting, expensive operations can end up in unexpected places. Compared to an explicit file read call, pointers to mapped files can easily spread through your code and leave you with blocking operations where you didn’t think you had them. Furthermore, this can make profiling your code more difficult, as code that’s not meant to block (e.g. async code) may subtly block the thread.
Hidden Contention and TLB Flushing
Page faults also have another way of hiding expensive operations, as they rely on constantly changing the page tables. Modifying page tables requires locking, which is handled in the kernel. Naturally, this is a source of contention: heavy use of page faults can cause contention in multithreaded applications, impeding read bandwidth. A related problem is traversing page tables, which isn’t free, so each CPU core maintains a Translation Lookaside Buffer (TLB), a cache of recent virtual to physical memory translations. We left this out of our diagram earlier, but it’s conceptually part of the MMU, which means the MMU doesn’t need to check page tables in RAM whenever it needs to translate an address. When the kernel evicts pages, it invalidates them from the virtual memory space, meaning the kernel needs to tell every CPU core to flush its TLB. Known as a TLB shootdown, this wipes every core’s MMU of recent translations. These issues mean that, bizarrely, heavy use of mmap in one thread can sneakily slow down all other threads in the process.
Can’t Keep up with NVMe
In recent years, NVMe SSDs have received significant uplifts in read bandwidth, with new consumer SSDs reaching over 10GB/second. Because of the performance problems with using mmap for disk IO, mmap can no longer keep up with the bandwidth available from storage today. This is exacerbated by the necessity of utilizing NVMe’s queues to reach its potential bandwidth, which mmap is unlikely to use effectively.
Conclusion
In conclusion, relying on mmap for disk IO has many significant performance pitfalls: increased memory usage, increased memory pressure, suboptimal page eviction, no non-blocking API, and several unexpected costs. To some extent, mmap can be tuned, but these are fundamental issues. Can we do better?
Sig’s Buffer Pool
As explained, we don’t want to rely on the kernel’s page cache or page faulting; however, doing entirely uncached reads isn’t ideal either. So, we need an in-process replacement for the page cache, a buffer pool that allows us to manage our memory explicitly, which is exactly what we implemented.
A buffer pool is a cache of memory frames managed by the application, holding recently used data to speed up reads and writes. When the program requests data, the buffer pool checks if it's already loaded into existing frames. If so, the request is served immediately. If not, the buffer pool explicitly reads data from disk into a free memory frame, evicting older frames if necessary.
Our buffer pool implementation uses many fixed-size and aligned frames, currently configured at 512 bytes each. These frames are allocated contiguously in a large region of memory. Note the frame size chosen is important—a larger frame size allows for less overhead but would also cause higher memory usage and reading more than we have to. We selected this size because over 95% of accounts are 200 bytes or less, meaning that a single 512-byte aligned read is enough to read most accounts.
For each frame, we store two atomic pieces of metadata: the reference count and whether it contains valid data. Each frame is also tracked by a hierarchical FIFO, which directs eviction. To look up frames, we use a standard hash map.
Our current implementation beats out mmap in most of our benchmarks while still having many potential optimizations available. More importantly, we’ve taken explicit control over our memory usage in AccountsDB, avoiding the high memory usage and memory pressure of mmap. As all of the buffer pool’s memory is now allocated upfront, our system can now perform more predictably. We’ve also taken control of eviction away from the kernel and made our blocking operations explicit.
Benchmarks
We compared the memory usage of mmap against the buffer pool by benchmarking each implementation 150 times. Since memory usage varied from run to run, we used the histograms below to visualize the results: the x-axis shows how much memory was used, and the y-axis shows how many runs used that amount.
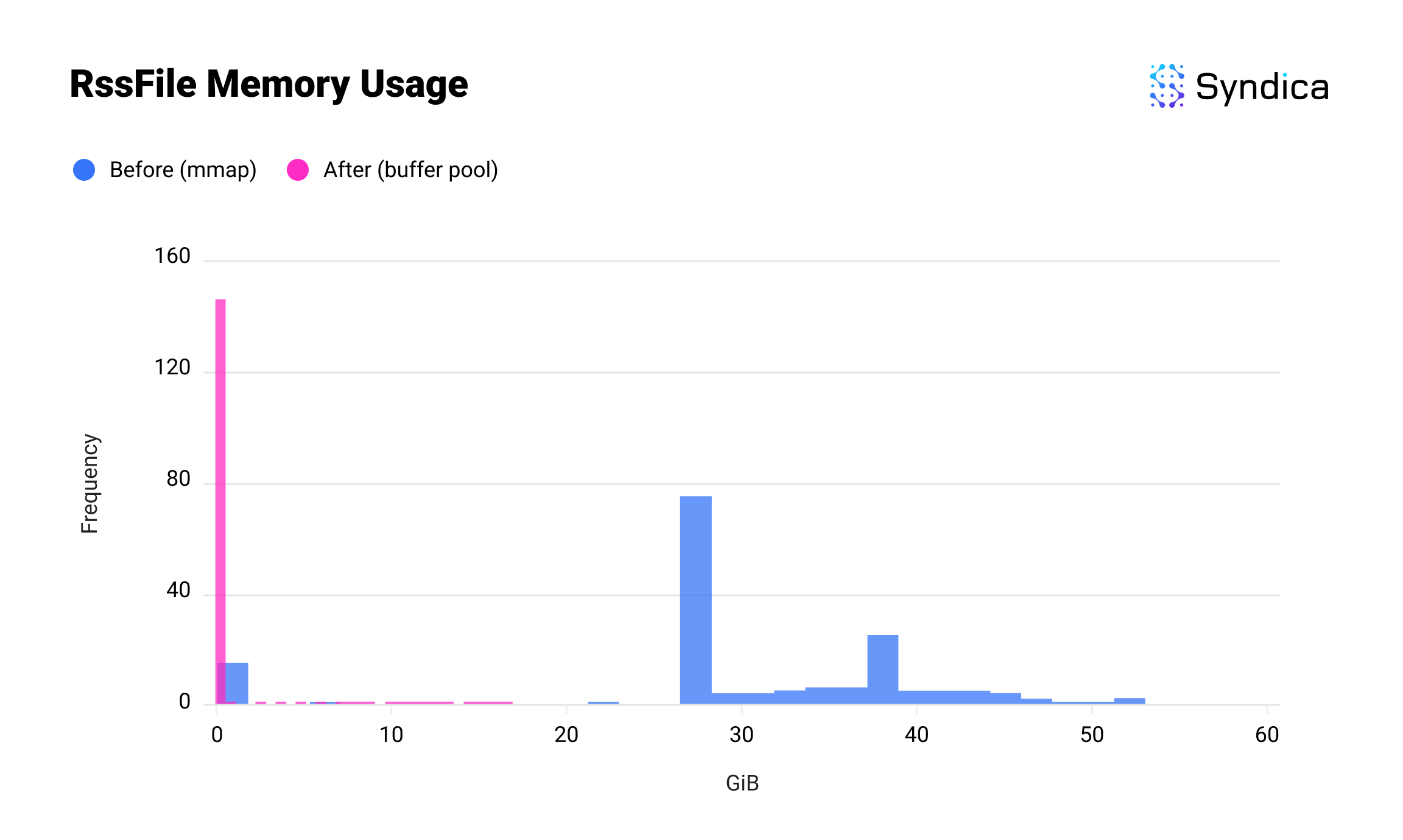
The first result is Sig’s usage of RssFile memory. RssFile refers to resident data (i.e. data currently in RAM), which is used for file mappings. After introducing the buffer pool, this memory usage went from dozens of gigabytes to approximately zero; if you can see a sliver of pink at the bottom, this is because of the account index, which is separate from this change.
And here’s the usage of RssAnon. RssAnon, or anonymous memory, accounts for all the ordinary memory allocations in physical RAM that are not backed by a file. This one is slightly higher, as we’ve brought memory that would have been in RssFile into RssAnon, but the combined total is significantly lower.
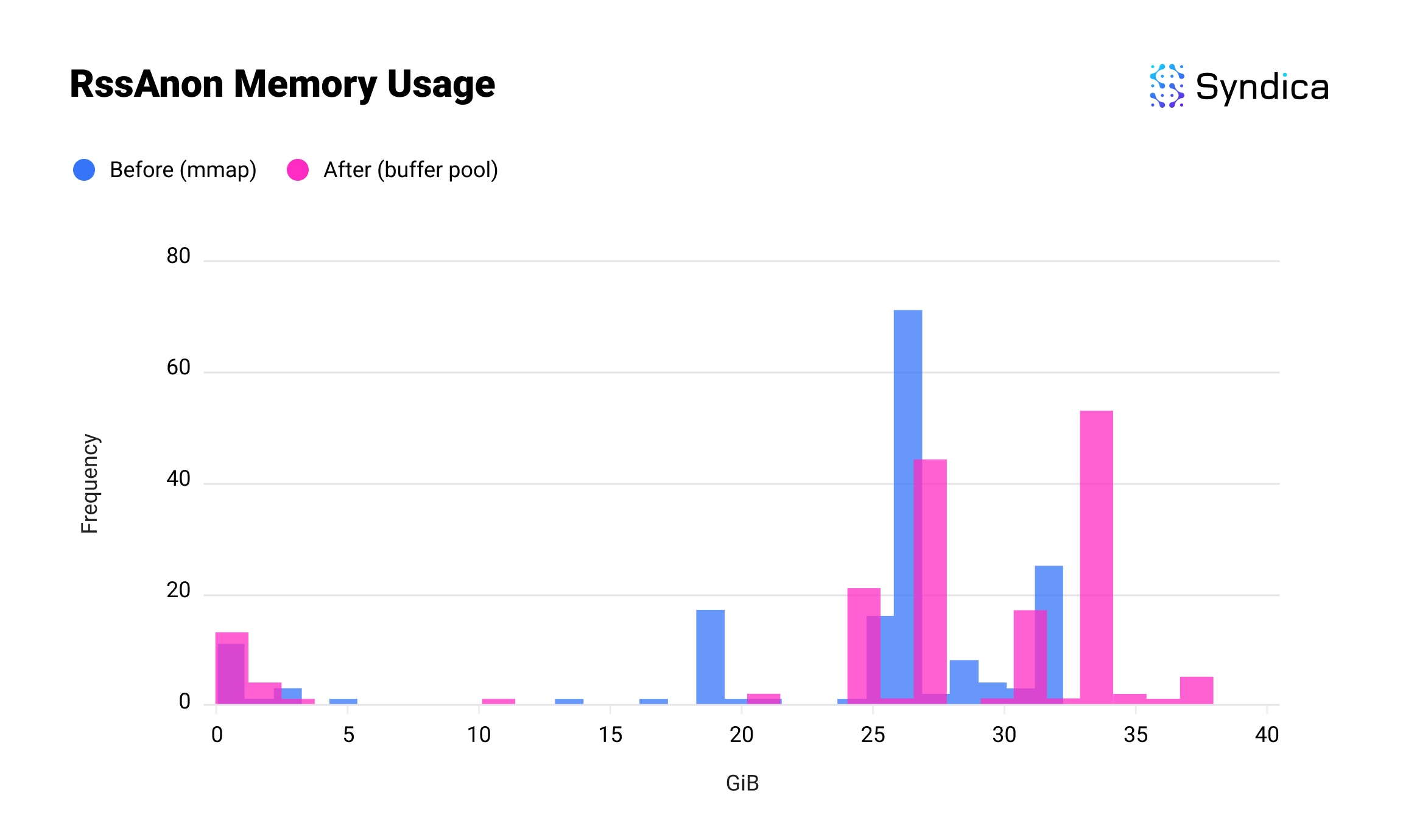
While this introduces complexity by moving memory management from the kernel into Sig, this is necessary to improve performance beyond what the kernel's general-purpose optimizations can offer. Initial benchmarks show that our buffer pool outperforms mmap in both memory efficiency and throughput.
Future improvements we have on the roadmap include:
- Creating a hash map designed for concurrent access.
- Multiple page sizes, similar to Linux's HugePages, would reduce the overhead of reading larger accounts.
- Non-blocking functions for pre-fetching account data.
- Open account files with the
O_DIRECTflag, which bypasses the kernel's page cache. Since we're already managing buffers in userspace, kernel caching is redundant, wastes memory, and introduces contention. - Using
io_uringby default, which is implemented but currently disabled since it requires some changes to improve performance.
For the full diff and some benchmarks, look at the pull request.
Gossip Memory Optimization
Gossip is the protocol that enables nodes to connect to each other and share metadata. It was the first component we implemented in Sig because it's so critical for all the other components in the validator. It was also the topic of our first blog post, which you can read here. At a bare minimum, any Solana validator—whether a full node or a light client—needs to run Gossip, so we'd like it to run as efficiently as possible.
In this section, we'll explore a memory optimization we implemented for Gossip that applies data-oriented design to efficiently store groups of related data.
Memory Usage
The Gossip Table is the essential data structure used for Gossip. It is an in-memory database that stores all the data received through Gossip. On mainnet, we found the Gossip Table's memory usage often reaches into the gigabytes, with most of that memory wasted as empty space. When running as a simple Gossip client, this accounted for the majority of Sig's memory usage.
Problem: Inefficient Tagged Unions
The inefficiency comes from the fact that the Gossip Table stores many different types of data, with each having a different size, but each is stored in a slot large enough to hold any of the allowed data types. In the Gossip Table, this “slot” is a tagged union called GossipData.
ContactInfo). To fit any of the allowed data types, the payload must always be the size of the largest data type. This is because the union's size must be determined when the code is compiled, but the type of the item it contains will not be known until later, at runtime.
This is how GossipData is defined:
pub const GossipData = union(GossipDataTag) {
LegacyContactInfo: LegacyContactInfo,
Vote: struct { u8, Vote },
LowestSlot: struct { u8, LowestSlot },
LegacySnapshotHashes: LegacySnapshotHashes,
AccountsHashes: AccountsHashes,
EpochSlots: struct { u8, EpochSlots },
LegacyVersion: LegacyVersion,
Version: Version,
NodeInstance: NodeInstance,
DuplicateShred: struct { u16, DuplicateShred },
SnapshotHashes: SnapshotHashes,
ContactInfo: ContactInfo,
RestartLastVotedForkSlots: RestartLastVotedForkSlots,
RestartHeaviestFork: RestartHeaviestFork,
};
And these are the sizes of the data types supported by GossipData:
| Data Type | Size (bytes) |
|---|---|
| ContactInfo | 608 |
| LegacyContactInfo | 368 |
| { u8, Vote } | 168 |
| RestartLastVotedForkSlots | 144 |
| SnapshotHashes | 128 |
| RestartHeaviestFork | 96 |
| { u8, LowestSlot } | 96 |
| { u16, DuplicateShred } | 80 |
| Version | 64 |
| { u8, EpochSlots } | 64 |
| LegacyVersion | 56 |
| LegacySnapshotHashes | 56 |
| NodeInstance | 56 |
| AccountsHashes | 56 |
ContactInfo is the largest allowed type at 608 bytes, and the tag is 4 bytes, which means every instance of GossipData requires 612 bytes. However, many items are much smaller than this, such as EpochSlots, which only needs 64 bytes. Storing an EpochSlots in a tagged union large enough to hold a ContactInfo wastes 544 bytes on empty space.
On mainnet, less than 1% of Gossip items are ContactInfo, while nearly 90% are EpochSlots, resulting in a lot of wasted space. This design was common to both Sig and Agave, so both clients had similar memory waste.
Solution: Data-Oriented Storage
Conceptually, the fix is simple: instead of wrapping each item in a GossipData, we store the inner variants directly without a tagged union. Previously, there was one big array of GossipData items containing every database entry. Now, each variant of the tagged union gets its own specialized array.
Since each array is specialized for a particular data type, we know at compile-time the actual amount of memory needed to store each item. No memory is wasted on a tag or extra space to hold larger items. This has reduced Gossip Table memory usage by 80%.
The memory layout previously looked like the image on the left, but now it more closely resembles the image on the right.
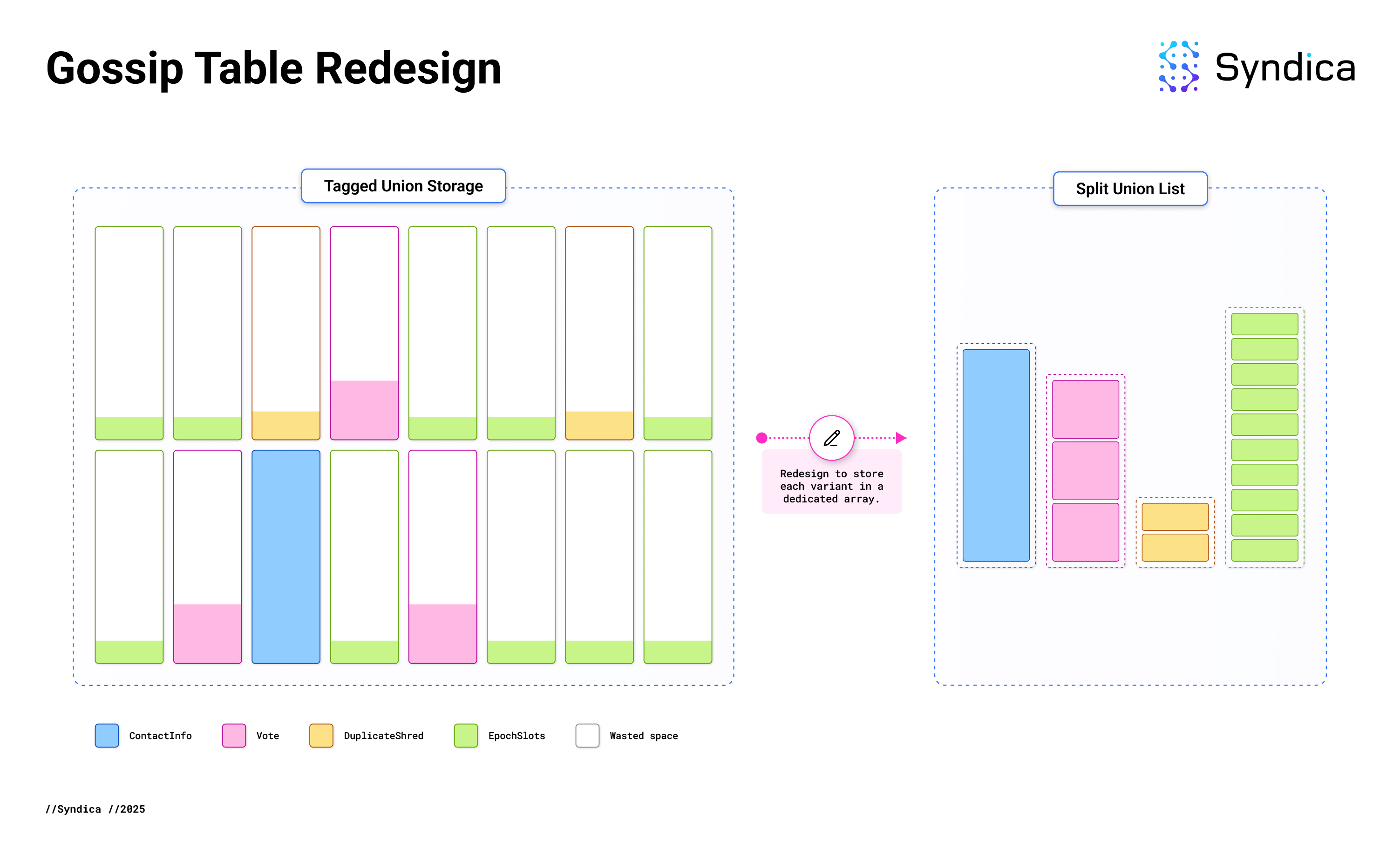
This is an application of data-oriented design, a programming technique that organizes code based on memory layout, and is particularly beneficial for performance-critical, data-intensive applications like a Solana validator.
Since storing collections of tagged unions is a common pattern, with other examples in Sig, we developed a general-purpose data structure, SplitUnionList, to simplify and generalize this optimization.
SplitUnionList
SplitUnionList is a generic list type that is designed to store tagged unions efficiently. It has a similar API to ArrayList, making it a convenient replacement. As a generic, a SplitUnionList can be configured to store any tagged union. The concrete version that holds instances of GossipData is SplitUnionList(GossipData).
Internally, SplitUnionList contains a separate array for each variant of the tagged union it's configured to store. If SplitUnionList(GossipData) were written out explicitly, it would look like this:
pub const GossipDataSplitUnionList = struct {
LegacyContactInfo: ArrayListUnmanaged(LegacyContactInfo),
Vote: ArrayListUnmanaged(struct { u8, Vote }),
LowestSlot: ArrayListUnmanaged(struct { u8, LowestSlot }),
LegacySnapshotHashes: ArrayListUnmanaged(LegacySnapshotHashes),
AccountsHashes: ArrayListUnmanaged(AccountsHashes),
EpochSlots: ArrayListUnmanaged(struct { u8, EpochSlots }),
LegacyVersion: ArrayListUnmanaged(LegacyVersion),
Version: ArrayListUnmanaged(Version),
NodeInstance: ArrayListUnmanaged(NodeInstance),
DuplicateShred: ArrayListUnmanaged(struct { u16, DuplicateShred }),
SnapshotHashes: ArrayListUnmanaged(SnapshotHashes),
ContactInfo: ArrayListUnmanaged(ContactInfo),
RestartLastVotedForkSlots: ArrayListUnmanaged(RestartLastVotedForkSlots),
RestartHeaviestFork: ArrayListUnmanaged(RestartHeaviestFork),
};
However, this explicit form is not necessary. SplitUnionList's fields are automatically generated from the tagged union when the code is compiled. In most languages, this would be impossible or require complex macros, but Zig makes it easy by allowing types to be manipulated at compile-time, just like ordinary data.
Specifically, SplitUnionList is implemented using the EnumStruct function. It takes two inputs: an enum type representing the union tag and a function to generate a field type from each variant.
pub fn EnumStruct(comptime E: type, comptime Data: fn (E) type) type {
@setEvalBranchQuota(@typeInfo(E).Enum.fields.len);
// Initialize an array for the struct fields.
var struct_fields: [@typeInfo(E).Enum.fields.len]StructField = undefined;
// Iterate over each enum variant.
for (&struct_fields, @typeInfo(E).Enum.fields) |*struct_field, enum_field| {
// Determine the type to use for the
// field derived from this variant.
const T = Data(@field(E, enum_field.name));
// Add a field to the array of struct fields,
// using the same name as the enum variant,
// and the type that was calculated above.
struct_field.* = .{
.name = enum_field.name,
.type = T,
.default_value = null,
.is_comptime = false,
.alignment = @alignOf(T),
};
}
// Generate and return a struct that contains
// the newly created fields.
return @Type(.{ .Struct = .{
.layout = .auto,
.fields = &struct_fields,
.decls = &.{},
.is_tuple = false,
} });
}
SplitUnionList is defined by calling EnumStruct with two arguments: the union's tag and a function that maps each variant to its corresponding ArrayListUnmanaged.
pub fn SplitUnionList(TaggedUnion: type) type {
// Derive the tag from the tagged union (i.e. GossipDataTag).
const Tag = @typeInfo(TaggedUnion).Union.tag_type.?;
return struct {
// The struct where each tag corresponds to a field with an ArrayList.
lists: sig.utils.types.EnumStruct(Tag, List),
};
}
GossipMap
While SplitUnionList behaves like a list, we need a map-like API to support get and put operations. To achieve this, we implemented the GossipMap struct.
GossipTable was initially implemented with a hash map from the standard library:
pub const GossipTable = struct {
store: AutoArrayHashMap(GossipKey, GossipVersionedValue),
...
It now contains GossipMap in its place:
pub const GossipTable = struct {
store: GossipMap,
...
While AutoArrayHashMap is backed by a single array, GossipMap is a hash map with a similar API that is backed by SplitUnionList, storing each union variant in a separate array.
Note that the value in the store has the type GossipVersionedValue, which is a struct (not a tagged union) that contains GossipData plus additional gossip-specific metadata. To handle this metadata efficiently, GossipMap required custom logic instead of a generic approach. Specifically, GossipMap stores metadata separately from GossipData. This optimizes memory access patterns since metadata and GossipData are typically accessed independently.
pub const GossipMap = struct {
key_to_index: AutoArrayHashMapUnmanaged(GossipKey, SplitUnionList(GossipData).Index),
gossip_data: SplitUnionList(GossipData),
metadata: ArrayListUnmanaged(Metadata),
};
Adopting SplitUnionList has reduced Gossip Table memory usage by 80%. Furthermore, it has unlocked faster memory access by improving cache locality and reducing memory bandwidth requirements. This case study in data-oriented design has yielded a broadly applicable solution for efficiently storing tagged unions in performance-critical applications.
Conclusion
In this blog post, we discussed some memory improvements we’ve recently made in Sig. We implemented a buffer pool from scratch, gaining explicit control over memory usage in AccountsDB. We also implemented a more efficient storage method for tagged unions, eliminating memory waste from Gossip.
As we continue to build Sig, designing a memory-efficient validator is one of our key goals. We hope this post can spark discussion on validator memory usage and are excited to share other optimizations we make in future blog posts.


